
PWN堆基础
堆的学习流程
先了解ptmalloc的运行机制,对于堆运行机制的介绍
- ptmalloc_phenics 设置-CSDN博客
- ptmalloc的实现细节_ptmalloc bin-CSDN博客
- 参考视频:底层技术栈:在Linux上怎么实现C语言的malloc函数
- 一篇文章彻底讲懂malloc的实现(ptmalloc)_malloc过程-CSDN博客
- glibc内存管理(华庭 庄明强)
然后再了解基本的漏洞成因比如UAF、off-by-one、unlink、堆溢出、off-by-null等漏洞
- 然后再去了解各个版本的堆漏洞利用的技巧
前置知识
内存布局
- 一个程序典型的内存布局如下图所示:从高地址到低地址分别为内核空间、栈、空闲区域、堆、bss、data、text。主要的就是这几个段,其他的可能有,但是不重要。
- 栈是自顶向下增长
- 堆是自底向上增长

虚拟内存机制
- 放CSAPP的博客里面
堆管理器的简单实现
常见的堆管理机制
1 | dlmalloc General purpose allocator |
ptmalloc
前面的这些内容主要是以glibc2.23版本的ptmalloc介绍,在介绍完2.23ptmalloc之后还会补充2.27新增的tcache和其他版本新增的ptmalloc管理机制
brk和mmap函数
- Linux系统向用户提供申请的内存有
brk(sbrk)和mmap函数
brk()和sbrk()
- 对于每个进程,内核维护着一个变量
brk,它指向堆的顶部。
1 |
|
这两个函数的作用就是扩展heap的上界brk。
- brk()的参数设置为新的brk上界地址,成功返回1,失败返回0.
- sbrk()的参数为申请内存的大小,返回heap新的上界brk的地址。
对于brk()运行过程如下图所示
1 | /*在程序刚开始运行的时*/ |
对于srbk()运行过程如下图所示
1 | //在程序刚开始运行,没有申请堆时,brk指针依然指向bss段的结尾 |
mmap()
1 |
|
Mmap的第一种用法是映射磁盘文件到内存中;第二种用法是匿名映射,不映射磁盘文件,而向映射区申请一块内存
Malloc使用的是mmap的第二种用法(匿名映射)
- Munmap函数用于释放内存
映射磁盘文件到内存中的过程
- 这里要注意mmap()和brk()/sbrk()这两种不同方式申请的堆内存是互相独立的,各自管理不同的内存区域,使用mmap时并不会自动调整brk指针。
1 | //初始状态 |
匿名映射的过程
1 | 高地址 |
Allocator
Malloc实现原理
- 因为brk、sbrk、mmap都属于系统调用,若每次申请内存,都调用这三个函数的其中一个,那么每次都会产生系统调用,会影响性能。
- 这样申请的内存容易产生碎片,因为堆是从低地址到高地址,如果高地址的内存没有被释放,低地址的内存就没办法回收
- malloc采用的是内存池的管理方式(ptmalloc),Ptmalloc采用边界标记法将内存划分成很多块(chunk),从而堆内存的分配与回收进行管理。
- 为了内存分配函数malloc的高效性,ptmalloc会将这些内存管理起来,并通过一些策略来判断是否将其回收给操作系统。
- 使用户申请和释放内存的时候更加高效,避免产生过多的内存碎片
chunk内存块的基本组织单元
- 在ptmalloc的实现源码中定义结构体malloc_chunk来描述这些块。
1 | struct malloc_chunk { |
简单说明chunk里面的数据
chunk结构体里面的数据可以结合后面的ptmalloc边界标记法具体过程一起看
prev_size: 如果前面一个块是空闲的,该区域表示前一个chunk的大小,如果前一个chunk不空闲,该域无意义。
size:当前chunk的大小,并且记录了当前chunk和前一个chunk的一些属性(记录在size的最后3个位中),包括前一个chunk是否在使用中,当前chunk是否通过mmap获得的内存,当前chunk是否属于非主分配区
- fd和bk:
- 指针fd和bk只有当该chunk块空闲时存在,其作用是用于将对应的空闲chunk块加入到空闲chunk块链表统一管理
- 如果该chunk块被分配给应用程序使用那么这两个指针也就没有用(该chunk块已经从空闲链中拆除)了,所以也当做应用程序的使用空间,而不至于浪费
- 在ptmalloc实现中使用双向循环链表来组织空闲块
- 空闲chunk通常使用头插法插入到适当的空闲链表中,这就意味着后释放的空闲块在链表的前面,再次申请大小相同的chunk(大小相同这个词在这里用的不妥当,可以先这么理解,后面再深入)申请到的是最后被释放的相应大小的内存空间中。这一点是比较重要的,对于后续的pwn堆题uaf等需要明白这一点
- fd_nextsize和bk_nextsize:
- 当前的chunk存在于large_bin时,large_bin中空闲chunk是按照大小排序的,但同一个大小的chunk可能有多个。
- 增加的这两个字段可以加快遍历空间chunk,并满足需要的空间chunk
- fd_nextsize指向下一个比当前chunk内存大的第一个空间chunk(个人觉得是指向头结点,还不太清楚)
- bk_nextsize指向前一个比当前chunk内存小的第一个空闲chunk
- 同一大小的chunk块可能有很多空闲的,如果没有设置fd_nextsize和bk_nextsize这两个指针,那么就需要遍历所有相同大小的chunk之后,才能找到满足需要的大小的chunk。非常影响效率
- 如果该chunk块被分配给应用程序使用,那么这两个指针也就没有用(该chunk块已经从size链中拆除)了,这样也可以当做应用程序的使用空间,能较好的使用程序空间
chunk的结构视图
- chunk的结构可以分为使用中的chunk和空闲中的chunk。使用中的chunk和空闲的chunk数据结构基本相同,但是会有一些设计上的小技巧,可以节省内存空间
使用中的chunk
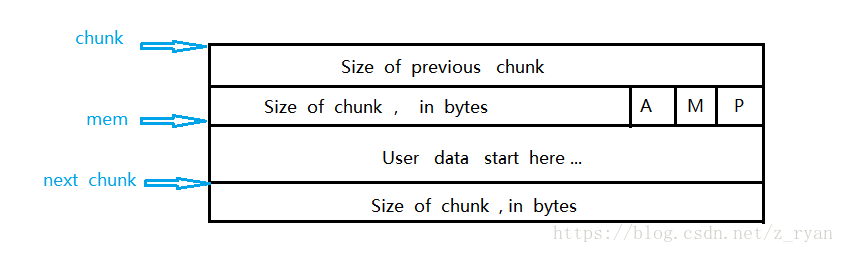
chunk、men、next_chunk
这三个指针,在一些函数中被定义为局部变量,然后通过计算,返回相应的地址
1 | // 获取用户数据部分的指针 |
- chunk指针指向chunk开始的地址
- men指针指向用户内存块开始的地址
- next_chunk指针指向的是下一个chunk中,size变量的位置,而不是prev_size变量的位置
size中的三个标志位A、M、P
- p=0时,表示前一个chunk为空闲,prev_size才有效
- p=1时,表示前一个chunk正在使用,prev_size无效p主要用于内存块的合并操作;ptmalloc分配的第一个块总是将p设置为1,以防止程序引用到不存在的区域
- M=1为mmap映射区域分配,M=0为heap区域分配
- A=0为主分配区分配,A=1为非主分配区分配
空闲的chunk
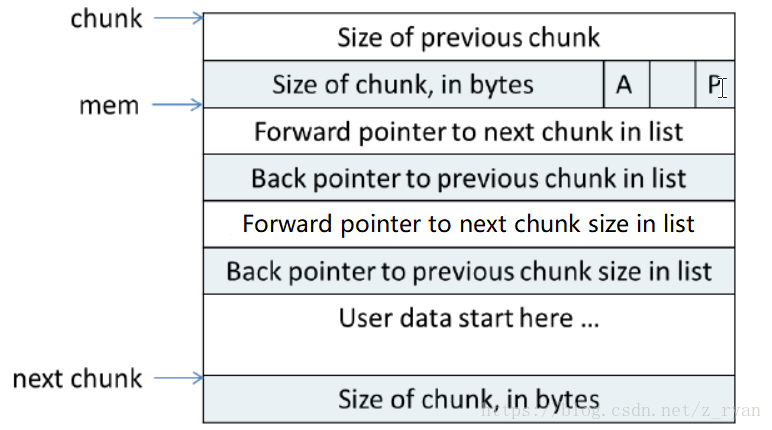
- 当chunk空闲时,其M状态是不存在的,只有AP状态(因为M表示是由brk还是mmap分配的内存,而mmap分配的内存free时直接ummap,不会放到空闲链表中。)换言之空闲链表中的都是brk分配的,所以不用额外记录
- 原本是用户数据的区域开头存储了四个指针
- 指针fd指向后一个空闲的chunk,bk指向前一个空闲的chunk,malloc通过这两个指针将大小相近的chunk连成一个双向链表
- 在large_bin中空闲chunk,还有两个指针,fd_nextsize和bk_nextsize,用于加快在large_bin中查找最近匹配的空闲chunk。不同的chunk链表又是通过bins或者fastbins来组织的(这里后面会介绍)
chunk中的空间复用
- 一个chunk或正在被使用,或者已经被free掉。为了使得chunk所占用的空间最小,ptmalloc使用了空间复用。所以chunk中一些域可以再使用状态和空闲状态表示不同的意义。来达到空间复用的效果
- 空闲时,一个chunk中至少要4个size_t大小的空间,用来存储prev_size、size、fd、bk,也就是16bytes。(注意:有时候chunk并不需要fd_nextsize和bk_nextsize,这个之后在空闲链表会介绍)
- chunk的大小要align到8bytes。当一个chunk处于使用状态时,它的下一个chunk的prev_size域肯定是无效的。这个域可以被当前chunk使用
- 所以,in_use_size=(用户请求大小+8-4)align to 8 bytes(这里的单位为字节)这里加8是因为需要存储prev_size和size,但又因为向下一个chunk“借”了4个bytes,所以要减去4。但是空闲的chunk和使用中的chunk使用的是同一块空间。要取这两者之间的最大值。所以最终分配的空间为chunk_size=max(in_use_size,16)。
注意:在后面的介绍中,如果不是特别指明的地方,指的都是这个经过转换的实际需要分配的内存大小,而不是用户请求的内存分配大小
空闲链表bins
- 首先bins是一个链表数组,用来管理一系列的chunk。
- 总体预览,ptmalloc中定义了malloc_state结构体用来统一管理bins。(而不是分别声明fast_bin、unsorted_bin),这就可以使他们在内存上是线性关系的。
1 |
|
- 当用户使用free函数释放掉内存,ptmalloc并不会马上将其交给操作系统,而是被ptmalloc本身的空闲链表bins管理起来。
这样当下次进程需要使用malloc申请堆内存的时候,ptmalloc就会从空闲的bins上寻找一块合适大小的内存块分配给用户使用。可以避免频繁系统调用,提高程序运行效率,降低内存分配开销
malloc将相似大小的chunk用双向链表链接起来,这样的一个链表被称为一个bin。ptmalloc一共维护了128个bin(也就是说维护了128个双向链表)。每个bins都维护了大小相近的双向链表chunk。根据chunk大小分为以下几种bins:
- Fast bin
- Unsorted bin
- Small bin
- Large bin
保存这些数据结构为
- fastbinsY:这个数组以保存fast_bins
- bins: 这个数组以保存unsorted、small以及large_bins,共计可容纳126个
当用户调用malloc的时候,能很快找到用户需要分配的内存大小是否在维护的bin上,如果在某一个bin上,就可以通过双向链表去查找合适的chunk内存块给用户使用
fast_bins中的chunk,size最后一位始终置1,这是为了防止fast_bin中chunk的内存合并
fast_bins
- 程序在运行时会经常需要申请和释放较小的内存空间。当分配器合并了几个相邻的几个小的chunk之后。也许马上就会有另一个小块内存的请求。这样分配器又需要从大的空闲内存中切分出一块,但是这样低效。
- 因此malloc引入了fast_bins
- fast_bins特点:当一个chunk被释放到fast_bins时,它不会立即被合并到相邻的空闲块中,即使有相邻的空闲块,这些块也不会被合成一个更大的块
工作机制
1.释放到Fast_Bins:当一个小的chunk被释放时,如果它的大小适合放入”fast_bins”中,那么它会被直接添加到对应的“fast_bin”链表中
2.分配内存:当需要分配一个小块内存时, 首先检查对应的”fast_bin”链表。如果链表中有可用的chunk,则直接从链表头部取出chunk进行分配
3.延迟合并:“fast_bins”中的块不会立即与相邻空间块合并。只有在执行内存分配操作,且需要更大的块时,或者在合适的时机(如进行垃圾回收或者重新分配时),才会将”fast_bins”中的块合并
链表介绍
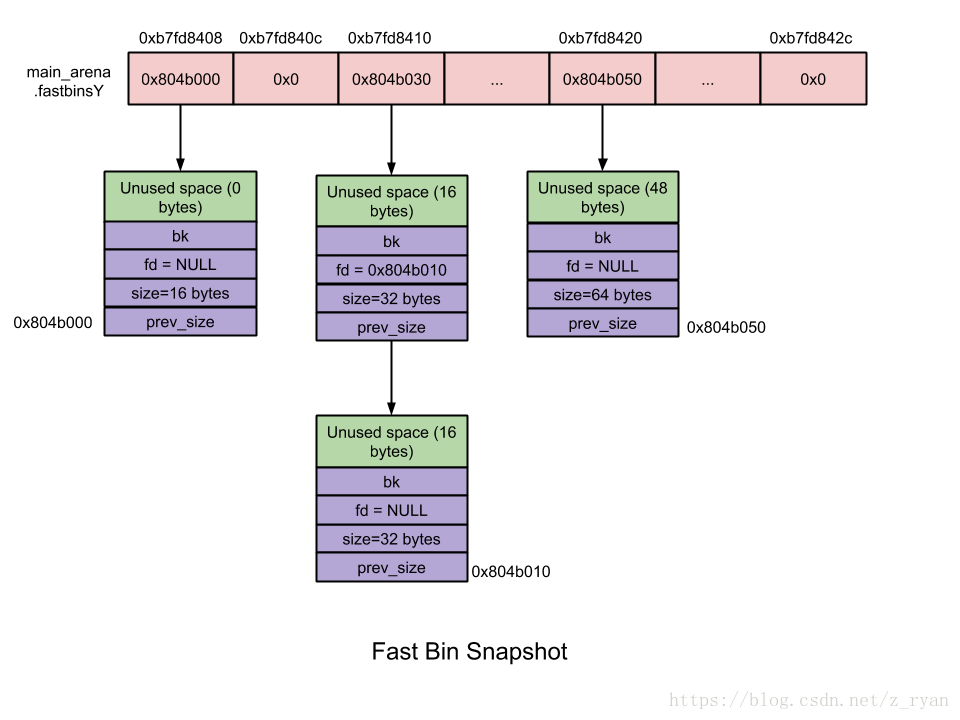
- fast_bin是bins的高速缓冲区,大约有10个定长队列。
- 每个fast_bin都记录着一条free_chunk的单链表,由于使用头插法,所以增删chunk都发生在链表的前端
- fast_bin数组记录着大小以8字节递增的bin链表,但是由于是在虚拟内存中,地址只占了4字节,剩下的高4字节就补0了
- 当用户释放一块不大于max_fast(默认值64B)的chunk的时候,会默认放到fast_bin上,当需要给用户分配的chunk小于或等于max_fast时,malloc首先会到fast_bins上寻找是否有合适的chunk。(一定大小内的chunk无论是分配还是是否都会先在fast_bin中过一遍,这里过一遍是指先根据请求的大小,求出对应的索引,然后直接查看该索引位置的链表,并不是直接遍历整个数组)
- 除非特定情况,两个毗连的空闲chunk并不会合成一个空闲的chunk。不合并可能会导致碎片化问题,但是却可以大大加速释放的过程
- 分配时binlist中被检索的第一个chunk,将被摘除并返回给用户。free掉的chunk将被添加在索引到的binlist的前端
unsorted_bin
- unsorted_bin的队列使用bins数组的第一个,是bins的一个缓冲区,加快分配的速度。当用户释放的内存大于max_fast或者fast_bins合并后的chunk都会首先进入unsorted_bin上
- chunk大小没有尺寸的限制。任何大小chunk都可以添加进这里。
- 这种途径给予glibc_malloc第二次机会以重新使用最近free掉的chunk,这样寻找合适bin的时间开销就没了。因此内存的分配和释放会更快一些
- 用户malloc时,如果在fast_bin中没有找到合适的chunk,则malloc会先在unsorted_bin中查找合适的空闲chunk,如果没有合适的bin,ptmalloc会将unsorted_bin上的chunk放入bins上然后到bins上查找合适的空闲chunk
small_bins
- 大小小于512字节的chunk被称为small_chunk,而保存small_chunks的bins被称为small_bin。
- small_bin每个bin之间相差8个字节,同一个small_bin中chunk具有相同的大小
- 每个small_bin都包括一个空闲区块的双向循环链表(也称binlist)。free掉的chunk添加在链表的前端,而所需chunk则从链表后端摘除。这与fast_bin所申请重复使用chunk的机制有所不同
- 两个毗连的空闲chunk会被合并成一个空闲chunk。合并消除了碎片化的影响但是减慢了free的速度
- 分配时,当small_bin非空后,相应的bin会摘除binlist最后一个chunk并返回给用户。在free一个chunk的时候,检查其前或其后的chunk是否空闲,若空闲则合并。也就是把它们从所属的链表中摘除并合并成一个新的chunk,新的chunk会添加在unsorted bin链表的前端
- 下面是small_bin的双向链表比较形象的图片
1 | +-------------------------------------------+ |
1 | smallbins[0] --> +-----------+ +-----------+ +-----------+ |
large_bins
- 大小大于等于512字节的chunk被称为large_chunk,而保存large_chunks的bin被称为large_bin,位于small_bins后面。
- large_bins中的每一个bin分别包含了一个给定范围内的chunk,其中的chunk按大小递减排序,大小相同则按照最近使用时间排序
- 两个毗连的空闲chunk会被合并成一个新空闲chunk
- 分配时,遵循原则“smallest-fist,best-fit”,从顶部遍历到底部以找到一个大小最接近用户需求的chunk。一旦找到,相应chunk就会分成两个块User chunk(用户请求大小)返回给用户
- Remainder chunk剩余部分添加到unsorted_bin。free和small_bin类似
三种特殊chunk
top chunk
- top_chunk相当于分配区的顶部空闲内存(可能就是由brk调用控制的brk指针),当bins上都不能满足内存分配要求的时候,就会来top_chunk上分配
- 当top_chunk大小比用户所请求大小还大的时候,top_chunk会分为两个部分:User_chunk(用户请求大小)和Remainder_chunk(剩余大小)。其中Remainder chunk成为新的top_chunk
- 当top_chunk大小小于用户所请求的大小时,top_chunk就通过sbrk(main arena)或mmap(thread arena)系统调用来扩容
mmaped chunk
- 当分配的内存非常大(大于分配阈值,默认128KB)的时候,需要被mmap映射,则会放到mmaped_chunk上。当释放mmaped_chunk上的内存的时候会直接交还给操作系统。chunk中M标志位置1
last remainder chunk
- Last remainder chunk是另外一种特殊的chunk,就像top_chunk和mmaped_chunk一样,不会在任何bins中找到这种chunk。当需要分配一个small_chunk大小,last remainder chunk被分裂成两个chunk,其中一个chunk返回给用户,另一个chunk变成新的last remainder chunk
unlink
- 在ptmalloc中
unlink函数用于从空闲链表中移除一个内存块。这个过程涉及调整链表指针以确保内存块被正确移除,并且其他空闲块的链接不会受到影响。 - unlink函数在glibc中存在两个版本,一个是过去使用的unlink还有一个是当前在使用的unlink
古老的unlink
- 旧版的
unlink函数负责将一个空闲块从双向链表中移除。这个过程需要更新表中的前向和后向指针,确保移除块之后,链表仍然保持正确的结构。 - 假设用一个空闲链表,由三个块A、B、C组成,每个块包含前向指针
fd和后向指针bk
1 | +---------+ +---------+ +---------+ |
- 当要移除中间的块B
- 先确定前后块,B块的前一个块是A块,B块的后一个块是C块
- 更新前一个块的fd指针,将A块的fd指向C块
- 更新后一个块的bk指针,将C块中的bk指向A块
- 移除块B之后的空闲块结构头如下
1 | +---------+ +---------+ |
当前的unlink
- 当前的unlink函数对移除块的操作和旧版的unlink函数一样,但是在移除的过程中多了检查
- 先要验证块的大小,确认当前块
P的大小与下个块next_chunk(P)的前一个块大小是否匹配,这里next_chunk(P)指的是与当前块P内存连续的块,而不是在逻辑上连续的块
1 | +-----------+ +-----------+ |
- 在验证完内存上的块大小是否匹配,接下来需要验证逻辑上块,指针指向的地址是否出现错误,如果错误就报错
1 | if (__builtin_expect (FD->bk != P || BK->fd != P, 0)) { |
- 接下来就是和旧版unlink一样的操作
区别
旧版本的
unlink和当前版本的unlink主要区别在于安全性和对指针操作的验证对于旧版的
unlink直接操作双向链表中的前向指针fd和后向指针bk,没有做太多的安全检查。这种实现方式比较高效,但是存在安全隐患,例如double free的堆漏洞会出现
1 |
|
- 当前版本的
ptmalloc通过添加多种安全检查来防止潜在的安全漏洞。例如在glibc 2.25中的unlink函数实现大致如下
1 |
|
补充
- 在large_bin中的检查
1 | // largebin 中 next_size 双向链表完整性检查 |
首次申请堆
- 在堆区中,start_brk指向heap的开始,而brk指向heap的顶部。
- 可以使用系统调用brk()和sbrk()来增加标识heap顶部的brk值
- 使得线性地增加分配给用户的heap空间
- 在使用malloc之前,brk的值等于start_brk,也就是说heap大小为0
- ptmalloc在开始时,若请求的空间小于mmap分配的阈值(mmap threshold,默认值为128KB)时,主分配区会调用sbrk()增加一块大小为(128KB +chunk_size)align 4KB(页面大小对齐)的空间作为heap。非主分配区会调用mmap映射一块大小为HEAP_MAX_SIZE(32位系统上默认为1MB,64位系统上默认为64MB)的空间作为sub-heap。这就是前面说的ptmalloc所维护的分配空间
- 当用户请求内存分配时,首先会在这个区域内(heap)找一块合适的chunk给用户。当用户释放了heap中的chunk时,ptmalloc又会使用fastbins和bins来组织空闲的chunk。以备用户的下一次分配
- 若需要分配的chunk大小小于mmap分配阈值,而heap空间又不够,则此时主分配区会通过sbrk()调用来增加heap大小,非主分配区会调用mmap映射一块新的sub-heap,也就是增加了top chunk的大小,每次heap增加的值都会对齐到4KB。
- 当用户请求超过mmap分配阈值,并且主分配区使用sbrk()分配失败的时候,或是非主分配区在top chunk中不能分配到需要的内存时,ptmalloc会尝试使用mmap()直接映射一块内存到进程内存空间。
- 使用mmap()直接映射的chunk在释放时直接解除映射,而不再属于进程的内存空间。任何对该内存的访问都会产生段错误。而在heap中或是sub-heap中分配的空间则可能会留在进程内存空间内,还可以再次引用(但是很危险)
分配区(arena)
分配区初学只需要稍微了解,等大致了解了ptmalloc后,可以再深入了解,多线程竞争题可能会考到
在ptmalloc中,内存分配管理区域主要分为主分配区(main arena)和非主分配区(non-main arenas)。这种设计是为了在多线程环境中提高内存分配和释放的效率,这样避免锁锁竞争
ptmalloc后续版本新增
tcache
参考博客:关于如何理解Glibc堆管理器(Ⅶ——Tcache Bins!!)_tcachebins-CSDN博客
- 在glibc 2.26版本开始引入了
tcache(Thread-Local Caching),以提高多线程程序的内存分配性能。ptmalloc2.27版本继承了这一机制,并在一定程度上优化了内存管理。
tcache结构
- 每个线程都有一个tcache_perthread_struct结构体,该结构体即为Tcache Bins的结构体
- 可以注意到,每个线程最多只能有64个Tcache Bin,且用单项链表储存free chunk,这与Fast Bin是相同的,且它们储存chunk的大小也是严格分类,因此这一点上也相同
1 | /* We overlay this structure on the user-data portion of a chunk when the chunk is stored in the per-thread cache. */ |
tcache分配内存
- 假如请求分配大小为32字节的内存块
- 先检查tcache_bins[0]是否有可用的块,如果找不到合适的块,则接下去找tcache_bins[1]链表里面的块
- 如果tcache_bins[0]中有可使用的块,那么就从中取出一个块,并移除
1 | 请求分配大小为 32 字节的内存块: |
释放块到tcache
- 假如释放一个32字节的内存块
1 | 释放大小为 32 字节的内存块: |
源码分析
- 操作tcache结构体的函数主要是一下两个
- 前者向Bins中放入chunk,后者则从中取出chunk。且每个Tcache Bin最多存放7个chunk
1 | /* This is another arbitrary limit, which tunables can change. Each |
- 当有tcache时的内存分配
1 | 内存申请: |
边界标记法
gdb关于堆的动调
相关指令
1 | 查看堆块信息 |
堆glibc环境
- 在了解堆进行实验或者示例程序的时候,本地ubuntu环境由于glibc版本和gcc版本的不同,导致有些示例程序运行不了。
这就需要搭建编译环境,试过很多办法,但是还是使用Docker容器比较方便。
可以直接使用
glibc-all-in-one这个github项目。这样就不用搭建docker环境,直接patchelf,在本地调试就行。
glibc2.23环境
- 在
Docker Hub上可以找到Ubuntu16.04版本的镜像,该版本的Ubuntu镜像通常会自带glibc2.23版本。 - 所以直接在Docker容器中做实验,如何下载Docker这边不做介绍具体看Docker概述与安装 | iyheart的博客
1 | docker pull ubuntu:16.04 |

- 然后再启动容器
1 | docker run -it --name glibc2.23 ubuntu:16.04 |

- 启动容器后就会自动进入所启动的容器内部,退出指令
exit - 如果要重新进入容器,需要先启动容器,然后再进入容器
1 | docker start <container_id_or_name> |
- 然后更新包管理器
1 | apt-get update |
- 然后再安装gcc编译器
1 | apt-get install gcc |
- 下载好后使用
gcc -v,查看gcc编译器的命令,glibc2.23兼容gcc版本一般是gcc 5的版本,ubuntu16.04在安装gcc的时候,会默认安装gcc 5的版本
- 剩下的
vim编辑器和gdb还有一些比较好用的终端,看着安装即可
glibc2.27环境
glibc2.27,是ubuntu18.04版本自带的,可以用Docker拉取Ubuntu18.04镜像
glib2.31环境
glibc2.31,是ubuntu20.04版本自带的,可以用Docker拉取Ubuntu20.04镜像
glibc2.33环境
glibc2.33,是ubuntu21.04版本自带的,可以用Docker拉取Ubuntu21.04镜像
glibc2.34环境
glibc2.34,是ubuntu21.10版本自带的,可以用Docker拉取Ubuntu21.10镜像
glibc2.35环境
glibc2.35,是ubuntu22.04版本自带的,可以用Docker拉取Ubuntu22.04镜像
glibc2.39环境
- 目前没有镜像自带glibc2.39,目前还不知道怎么搞这个环境
 wechat
wechat