
python基础语法3
- python代码的运行方式
- 进制
- 计算机中的单位
- 编码
Python代码运行方式
-
脚本式(先把Python代码写入到文件中)
-
交互式(在终端进入Python解释器,即进入交互式环境),缺点:关闭终端代码会消失
-
在Pycharm中也有交互式的运行
进制
- 计算机中底层所有的数据都以010101的形式存在(图片、文本、视频等)。
二进制
- 二进制(满二进一)
1 | 例: |
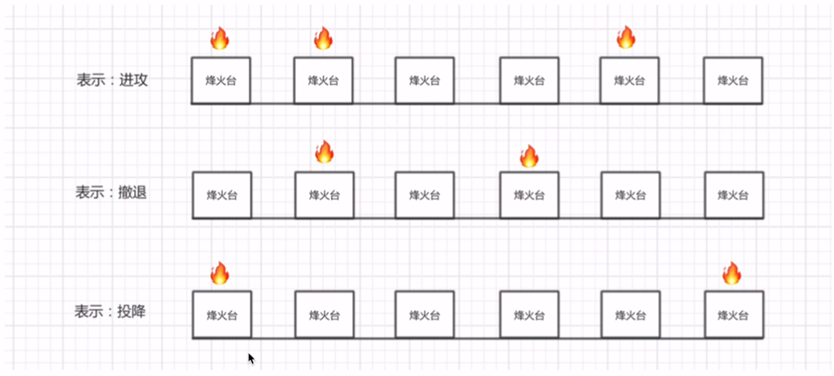
- 二进制就像古代烽火台的点燃一样一定的顺序代表一定的信号
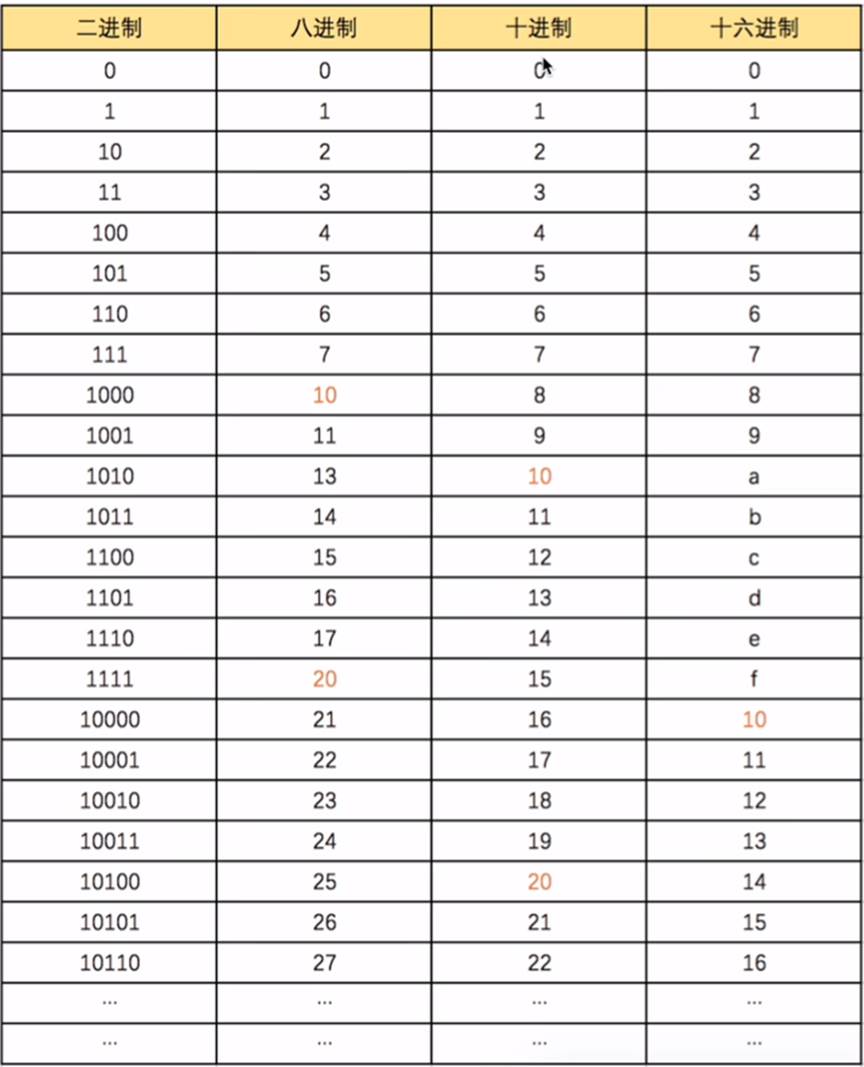
八进制、十进制、十六进制
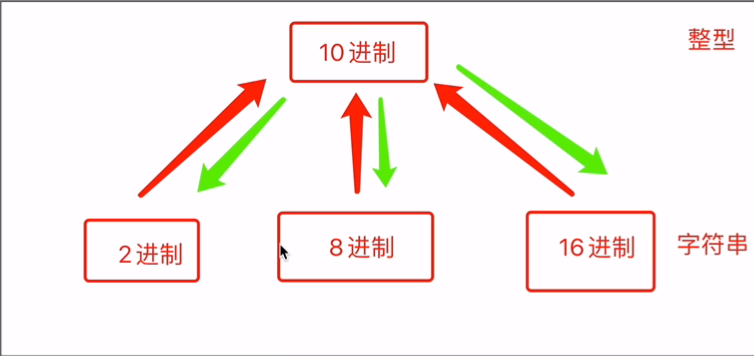
- 二进制、八进制、十进制、十六进制的相互转换
进制转换
-
注意:二进制和八进制和十六进制没有办法直接互相转换,需要借助10进制间接转换
-
十进制转化为其他进制
1 | 例: |
- 将二进制、八进制、十六进制转换为十进制
1 | i1 = int("0b11001",base=2) |
计算机中的单位
- 由于计算机中本质上所有的东西是以二进制存储和操作的,为了方便对于二进制值大小的表示,所以就搞了一些单位。
单位
- b(bit),位:
1 | 1,1位 |
- B(byte),字节:
1 | 10010110,1个字节 |
- KB(kilobyte),千字节:
1 | 1024个字节就是1个千字节 |
- M(Megabyte),兆:
1 | 1024KB就是1M |
- G(Gigabyte),千兆:
1 | 1024M就是1G |
- T(Terabyte),万亿字节:
1 | 1024个G就是1T |
- 其他更大单位PB/EB/ZB/YB/BB/NB/DB不再赘述。
练习
-
假设1个汉字需要2个字节(2B=16位来表示,如:1000101011001100),那么1G流量可
以通过网络传输多少汉字呢?(计算机传输本质上也是二进制) -
1G = 1024M = 1024 * 1024KB = 1024 * 1024 * 1024 B
每个汉字需要2个字节表示
1024 * 1024 * 1024/2 = ? -
假设1个汉字需要2个字节(2B=16位来表示,如:1000101011001100),那么500G硬盘可以存储多少个汉字?
500G = 500 * 1024M= 500 * 1024 *1024 KB = 500 * 1024 * 1024 * 1024 B
500 * 1024 * 1024 * 1024 / 2 = ?
编码
- 编码,文字和二进制之间的一个对照表全球的编码有很多种,下面介绍的是常见的编码
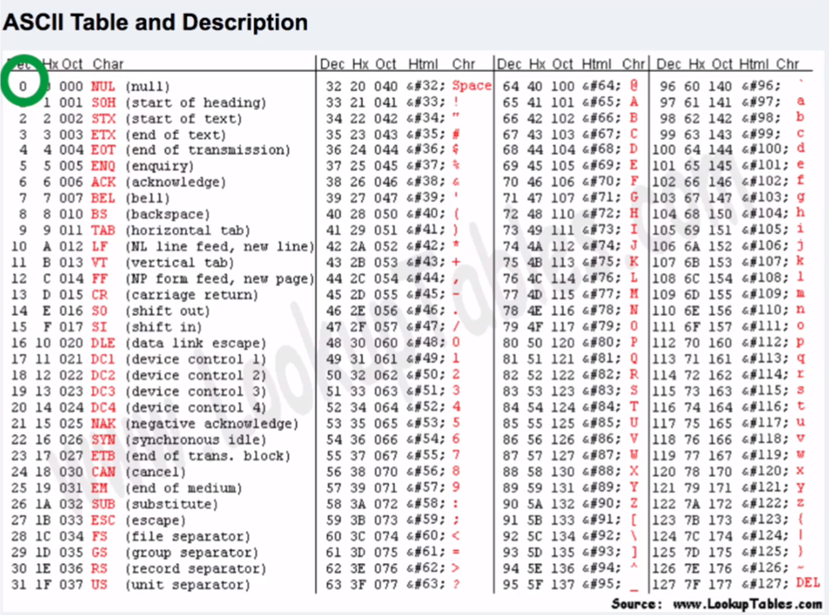
ASCII编码
- Ascii规定使用1个字节来表示字母与二进制的对应关系
1 | 00000000 |
gb-2312编码
- gb-2312编码,由国家信息标准委员会制作(1980年)
- gbk编码,对gb2312进行扩展,包含了中日韩等文字(1995年)
1 | 在与二进制做对应关系时,由如下逻辑: |
unicode
- Unicode也被称为万国码,为全球的每个文字都分配了一个码位(二进制表示)。一般使用两种标准来做为文字和码位的对应关系。
ucs2
1 | 用固定的2个字节取表示一个文字 |
ucs4
1 | 用固定的4个字节去表示一个文字。 |

注意:
-
在第三个符号中ucs2表示不了,要用ucs4,并且如果没有满4个字节前面需要补零。
-
无论是ucs2和ucs4都有缺点:浪费空间

-
如果把一堆A放入内存,那么 用ascii存储的如果是1个G,那么用ucs2存储的就是要2个G,用ucs4存储就要4个G
-
Unicode的应用:在文件存储和网络传输时,不会直接使用unicode。而在内存中unicode。
utf-8编码
- 包含所有文字和二进制的对应关系,全球应用最为广泛的一种编码(站在巨人的肩膀上功成名就)。
- 本质上:utf-8是对Unicode的压缩,用尽量少的二进制去与文字进行对应。左边的区间范围是16进制。

-
具体压缩的流程:
- 第一步:选择转换模板

- 第二步:在模板中填入数据

- 在套的时候,从后往前套,每六位套一字节
Python相关的编码
- 字符串(str) “alex媳妇叫铁锤” unicode处理 一般在内存
- 字符串(str) “alex媳妇叫铁锤” unicode处理 一般在内存
1 | v1 = "武" #unicode ucs4 |
- 将一个字符串写入到一个文件中
1 | # 将一个字符串写入到一个文件中。 |
总结
-
计算机上所有的东西最终都会成为二进制再去运行。
-
ascii编码、unicode字符集、utf-8编码本质上都是字符与二进制的关系。
- ascii,字符和二进制的对照表
-
unicode,字符和二进制(码位)的对照表
-
utf-8,对unicode字符集的码位进行压缩处理,间接也维护了字符和二进制的对照表。
-
ucs2和ucs4指的是使用多少个字节来表示Unicode字符集的码位。
-
目前最为广泛的编码为:utf-8,它可以表示所有的字符且存储和网络传输也不会浪费资源(对码位进行压缩了)。
-
二进制、八进制、十进制、十六进制其实就是进位的时机不同。
-
基于Python实现二进制、八进制、十进制、十六进制之间的转换。
-
一个字节8位
-
计算机中常见单位b/B/KB/M/G的关系。
-
汉字,用gbk编码需要用2个字节;用utf-8编码需要用3个字节。
-
基于python实现将字符串转换为字节(utf-8编码)
1 | # 字符串类型 |
- 基于python实现将字符串转换为字节(gbk编码)

 wechat
wechat

