
PWN堆UAF
- UAF漏洞,全名为
use after free漏洞,即在堆在free之后再进行使用。 - 在看本篇博客之前,先准备好Docker和Docker中
ubuntu16.04的版本镜像(其对应glib版本是2.23),并下载好gdb。- 如果有办法下载pwndbg这个插件尽量在镜像中下载,
pwndbg对于调试堆块还是很友好的 - 堆这块重要的是实验,所以能有环境就尽量使用环境,能更好的理解堆。(光看理论只能对堆了解个大概,真正的还是要通过实验和题目去理解)
- 可以看这篇博客,这里面有完整的dockerfile,直接使用Dockerfile就可以一键部署ubuntu16.04的环境在2024年如何成功搭建Ubuntu 16.04的pwn环境 - roderick - record and learn! (roderickchan.cn)
- 直接使用命令
docker run -it --rm roderickchan/debug_pwn_env:16.04-2.23-0ubuntu11.3-20240412 - 或者先拉取镜像
sudo docker pull roderickchan/debug_pwn_env:16.04-2.23-0ubuntu11.3-20240412
- 如果有办法下载pwndbg这个插件尽量在镜像中下载,
- 这里归纳一下要使用Docker的命令
1 | docker pull ubuntu:16.04 # 使用Docker命令拉取ubuntu16.04的镜像 |
前提介绍
- UAF是最常见的漏洞成因,有一些house of 打法都是由UAF造成的,所以要先学习UAF这个基础,才能学习打法
- 个人认为:基本漏洞成因:
UAF、off-by系列
漏洞原因
- 在堆管理机制中,调用free(*ptr)函数后,会将ptr所指向的那个
chunk给释放掉,但是不会将ptr设置为NULL,这需要程序员编写代码手动设置为NULL - 由于程序员的疏忽,没有将
ptr的值设置为NULL,或者没有将ptr指向其他堆块。这就会导致可以再次利用该指针,对所释放的那个堆块内存进行一些操作
三种情况
- 内存块被释放后,其对应的指针被设置为NULL,然后再次使用,自然程序会崩溃
- 内存块被释放后,其对应的指针没有被设置为NULL,然后在它下一次被使用之前,没有代码对这块内存进行修改,那么程序很有可能可以正常运转
- 内存块被释放后,其对应的指针没有被设置为NULL,但是在它下一次使用之前,有代码对这块内存进行了修改,那么当程序再次使用这块内存时,就很有可能会出现奇怪的问题
故Use After Free漏洞名称就是字面意思,利用的就是后两种机制。一般称被释放后没有被设置为NULL的内存指针为:dangling pointer
示例程序
实验一
- 在宿主机写代码并编译即可(需要使用pwndbg插件),写完该段代码,编译后使用pwndbg插件进行动态调试
- 思考:
- malloc传入参数是多少,就会分配多少的堆内存吗?会有分配的最小内存值吗?需要进行对齐操作吗?
1 |
|
分析1
- 先动态调试将程序执行到该处
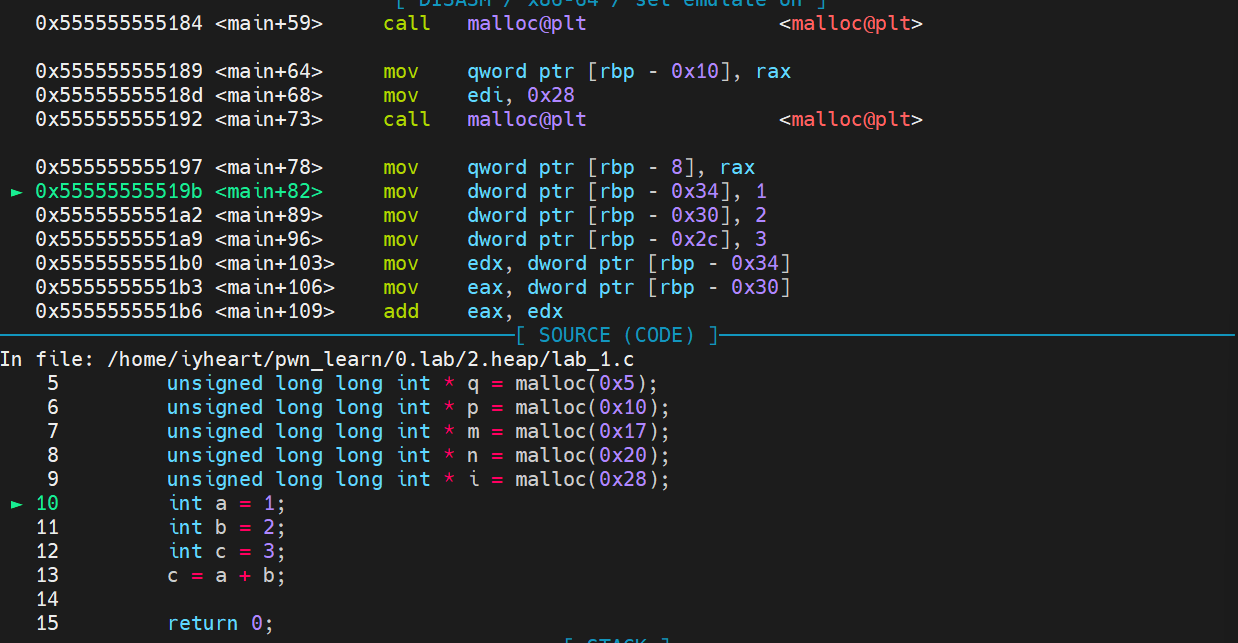
- 然后使用
heap命令查看堆块,发现了当malloc参数分别为0x5、0x10、0x17的时候分配得到的堆都是0x20, - 当malloc参数为
0x20、0x28的时候分配得到的都是0x30
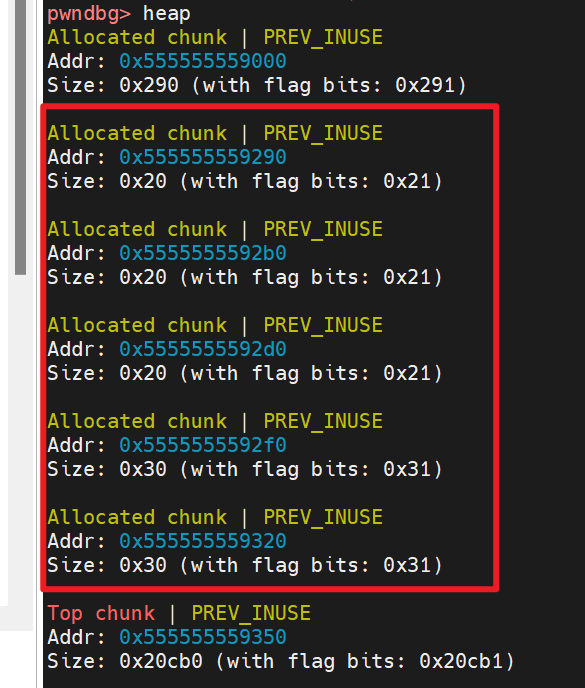
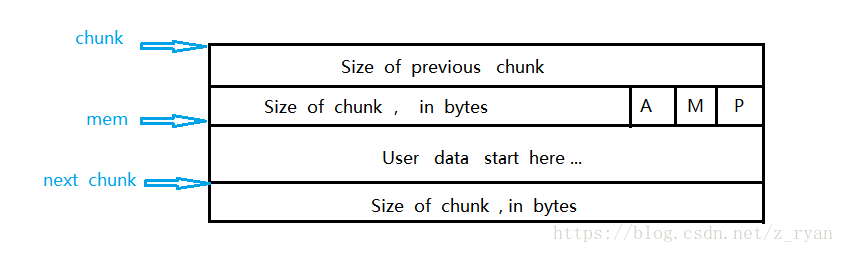
- 这是因为当我们申请一个堆块且申请的堆块比较小的时候,使用中的chunk数据结构如下
- 这里看到chunk需要占用而外的
0x10字节去存储previous_size、size - 同时chunk在使用的时候
previous_size是不存数据的,这样就可以通过空间复用将该内存给上一个正在使用的chunk保存数据
- 这里看到chunk需要占用而外的
- 而当空闲时的堆块数据结构如下
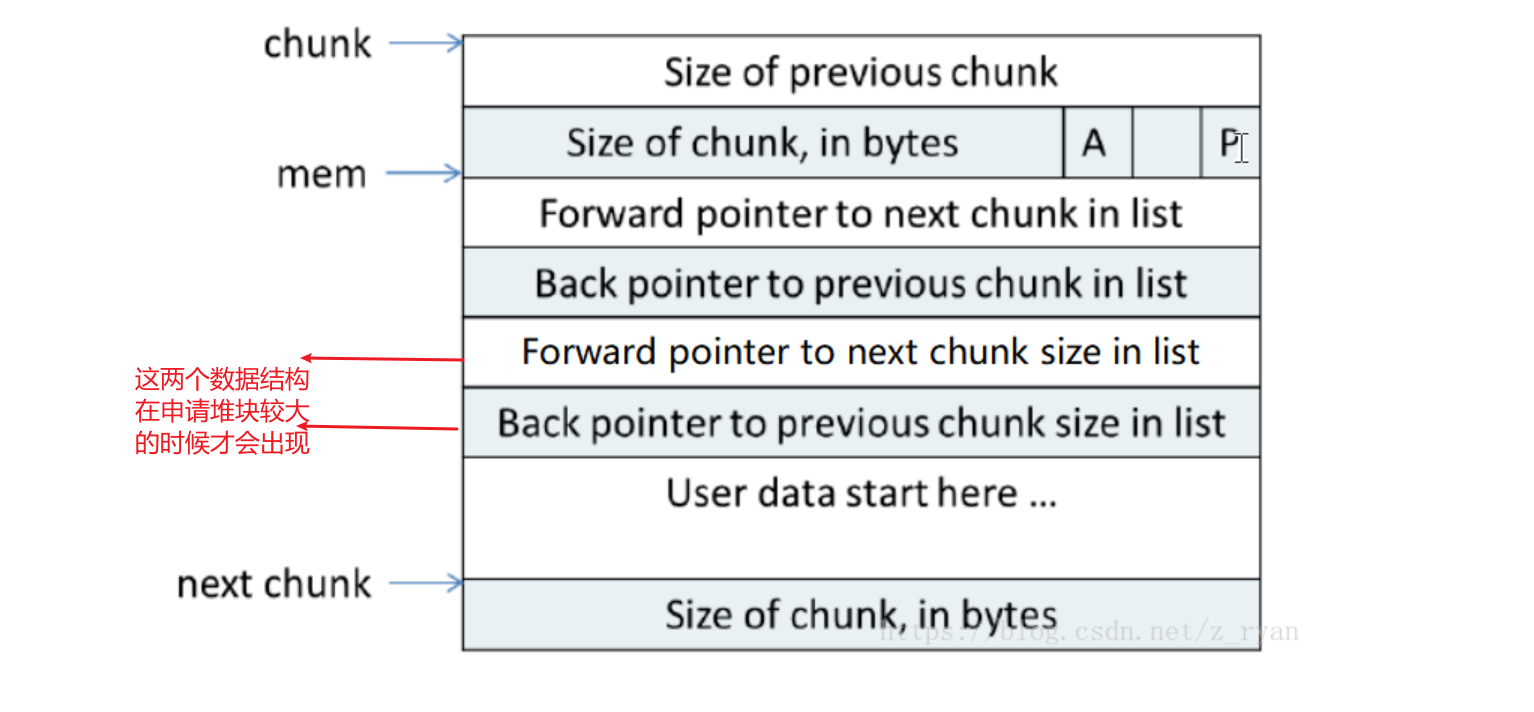
- 为了能保证空闲时堆能存储其数据结构,所以使用malloc申请空间时最小都要保证
previous_size、size、fd、bk要有内存。而在64位中这些类型的变量大小均为8字节,所以他们就会占用0x20的空间。故当使用malloc函数申请的内存小于一定程度时会默认分配0x20大小的堆块,最后在64位计算机上,申请的堆块要与0x10对齐(32位计算机是与0x8对齐) - 所以当我们
malloc参数分别为0x5、0x10、0x17- 申请0x5时,要使用chunk:
0x5+0x10-0x8 =0xD要与0x10对齐所以结果为0x10,但是0x10的空间又不够存储previous_size、size、fd、bk。故malloc会分配0x20字节的空间- 其中加上0x10chunk在使用时有
previous_size、size - 减去0x8是因为向下一个chunk“借”了0x8个字节
- 其中加上0x10chunk在使用时有
- 申请0x5时,要使用chunk:
分析2
-
当我使用
malloc函数申请了0x20的字节为什么使用中的chunk的大小是0x30 -
安装分析1的方法计算
0x20 + 0x10 - 0x8 = 0x28与0x10对齐,故得到的是0x30的块大小 -
申请0x28也是一样的
-
总结:
- 当计算用户申请的堆块大小m有**
m + 0x10 -0x8对齐0x10**最后结果小于或等于0x20的时候,系统自动分配0x20的内存 - 当计算用户申请的堆块大小m有**
m + 0x10 -0x8对齐0x10**最后结果大于0x20,内存按计算的结果分配
- 当计算用户申请的堆块大小m有**
实验二
- 该实验的环境是在
glibc2.23即ubuntu16.04版本下自带的环境 - 思考一下为什么会出现这个问题:
- 注意:fast_bins、malloc(0x10)是否真的分配0x10的空间、chunk在使用时的数据结构、chunk在空闲时的数据结构、如何伪造堆块。
1 |
|

分析1
- 这里malloc(0x10)实际分配多少内存空间不做介绍了。可以看到申请的堆地址为
0xff5010,记下该地址 - 接下来分析一下malloc与free之后的
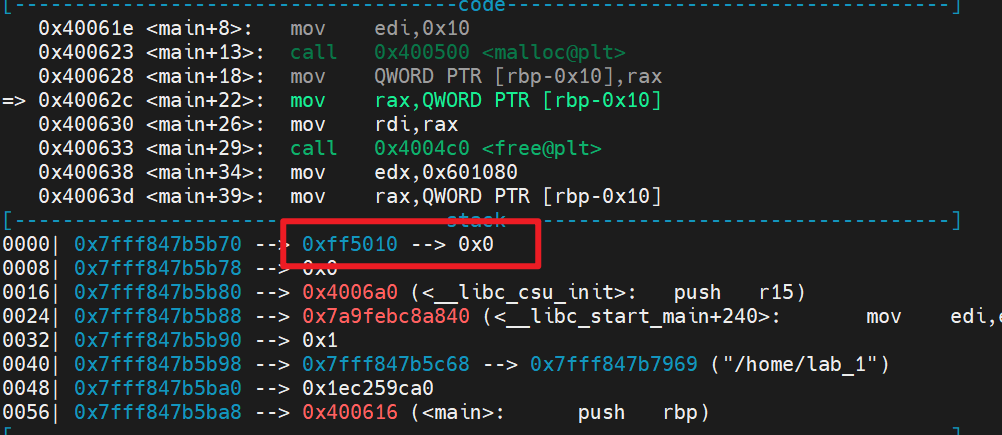
- 当free(p)之后,p所使用的内存空间被释放了,但是p值仍是之前申请的内存空间地址,并没有被置
NULL
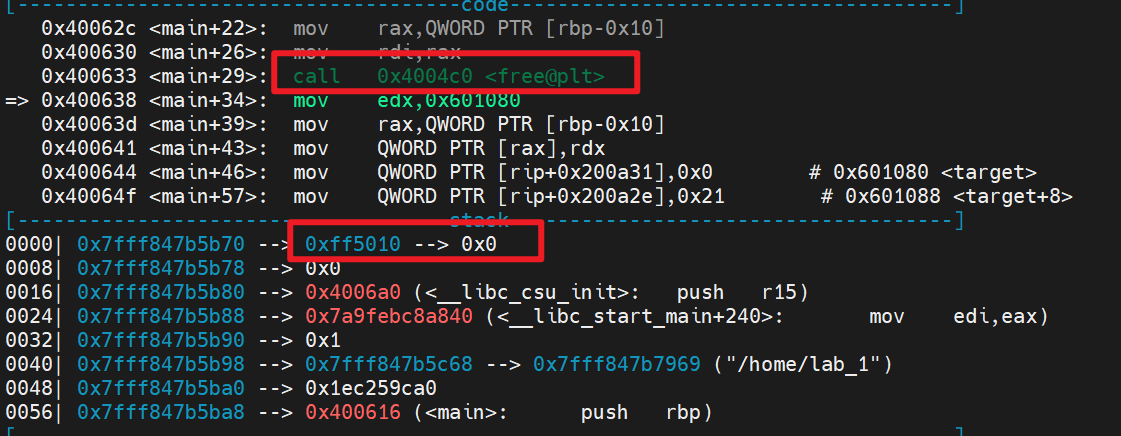
- 并且根据堆块的大小,被释放的chunk,被
fast_bins管理着,但由于p没有被置NULL,所以他还是指向该位置(这与malloc的返回值有关)- 由于是第一次malloc,因此前一个
chunk不存在或正在使用,P位应为1,所以size是0x21而不是0x20 - 由于P标志位,为1,那么Prev_size的值要为0或未使用
- ptmalloc分配的第一个块总是将p设置为1,以防止程序引用到不存在的区域
- 还是要值得注意一点:p标准位表示当前堆块的前一个堆块是否空闲,
1表示在使用,0表示空闲,如果空闲chunk就会与其他p标志位为0的堆块合并。但是,当free一个堆块的时候,如果该堆块被fastbin管理,那么他的后一个堆块的p标志位仍然为1,并不会被合并
- 由于是第一次malloc,因此前一个

分析2
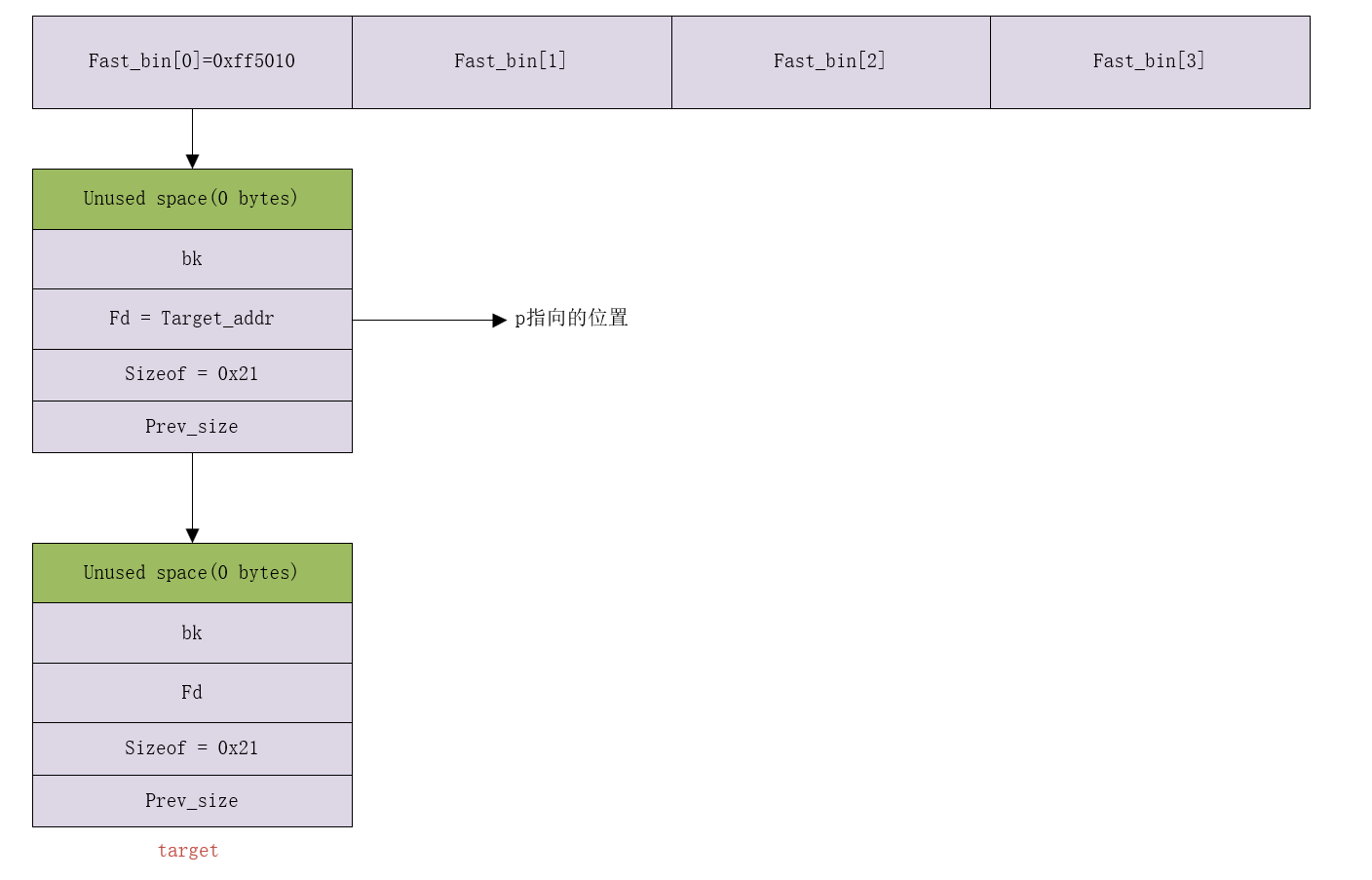
- 使用target伪造堆块
1 | p[0]= target; |
- 修改空闲堆块中的Fd指针,使其指向target。
- 然后修改target的第一个8字节,即伪造
Prev_size - 伪造第二个8字节即
sizeof = 0x21,0x20是表示chunk大小,最后一位的1表示P标志位。fast_bin链表就形成了这么一个链表
分析3
- 当申请一个相同大小的chunk时,即
malloc(0x10),这样就会将直接与fast_bin[0]连接的chunk块给申请回去 - 然后
fast_bin[0]的管理如下
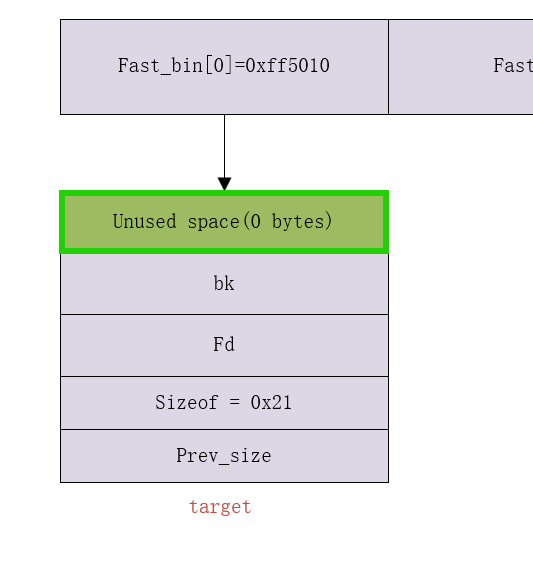
-
当
char *q = malloc(0x10);时,fast_bin里面还有堆块(伪造的),这时也会被申请过来,并且malloc返回的地址为Fd的位置,然后写入数据时,从fd、bk、unused space、next_chunk_prev_size方向增长 -
知道了以上这些后,再查看接下来的代码,就知道为什么程序编译执行后会输出
hello了
1 | memcpy(q,"hello",6); |
UAF利用方法
题目1–level_1
-
来源:PolarCTF2023秋季个人挑战赛,题目名称:heap_Easy_Uaf
-
题目附件:下载:https://wwsq.lanzoue.com/iI8DK29800xi 密码:6fh1
分析
- 先使用
file命令查看附件的信息 - 发现是64位的ELF文件,动态链接

- 再使用
checksec命令查看保护机制 - 开启了
Canary和NX保护
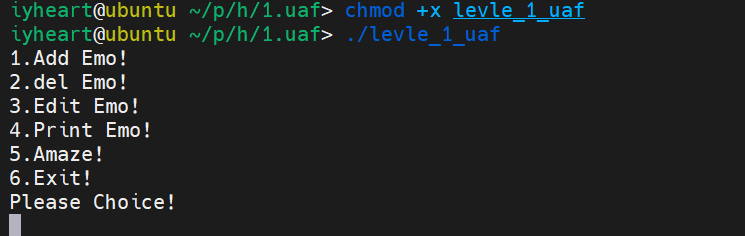
- 接下来试着运行一下程序,发现是典型菜单题目
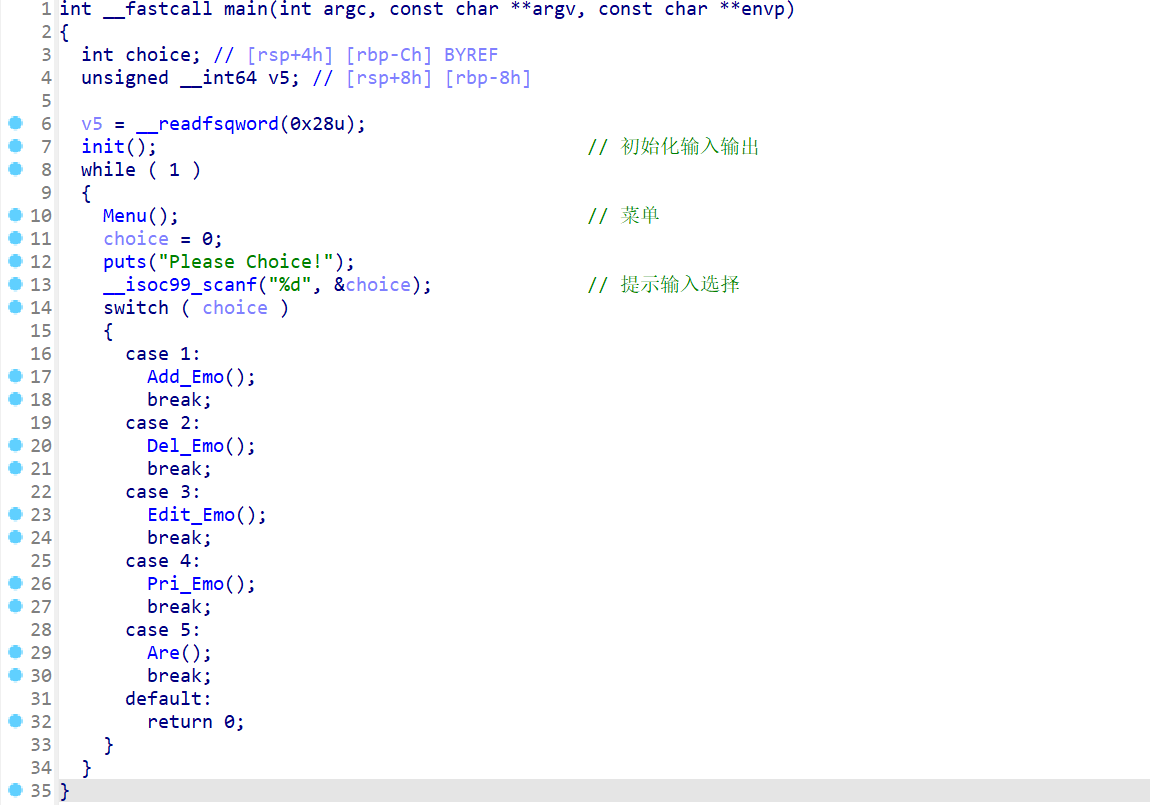
- 将该程序拖入IDA,进行反编译查看,接下来是查看过程
-
对于
Add、Del、Edit、Pri是基本的增、删、改、输出。这些找不到漏洞- Add申请指定大小的堆块,并可以写入相应大小的内容
- Del释放堆块,并将指向堆的指针置0
- Edit修改堆块,修改指定堆块的内容只能修改
0x20字节 - Pri打印堆块,输出指定堆块里面的内容
-
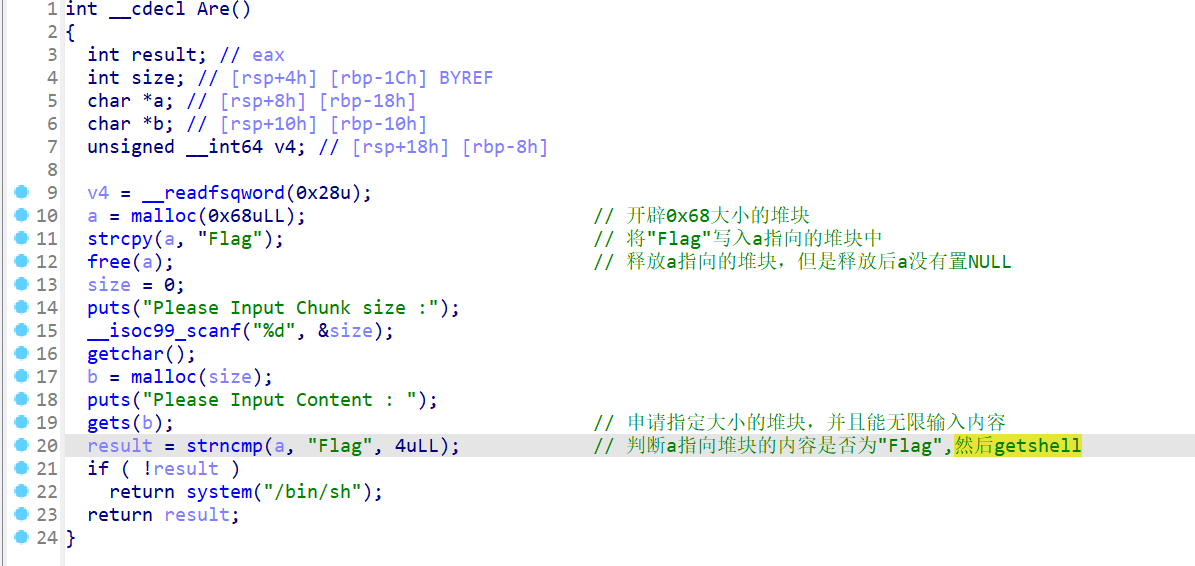
但是对于
Are这个我们还是不太清楚什么功能,进行仔细的查看、- 发现题目直接给了shell
- 然后题目存在uaf漏洞,释放完a指向堆块后并没有置NULL,但是里面的
Flag字串会被改变
利用
- 当释放a指向的chunk时,由于是glibc2.23,该chunk会被
fast_bin所管理
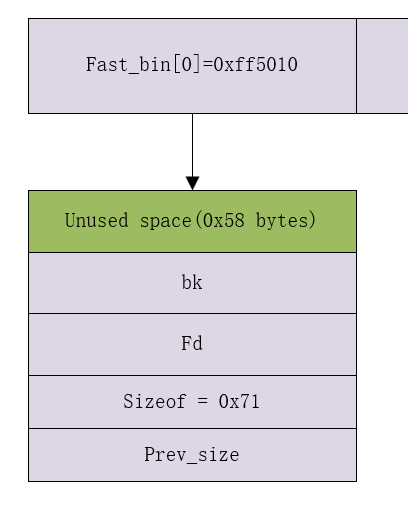
- 当我们再申请一个堆时,ptmalloc会检查申请堆块大小和管理的堆块大小是否一致,如果一致那么就会将前面释放的堆块拿来用。这样b所指向的堆块和先前a所指向的堆块就是同一个堆块
- 这时我们再编辑堆块b为
Flag这样就可以getshell - 完整exp如下:
1 | from pwn import * |
题目2–level_2
- 来源:PolarD&N (polarctf.com),pwn题,简单部分,
ezuaf - 附件:https://wwsq.lanzoue.com/i6LSk29wbkyj 密码:ebch
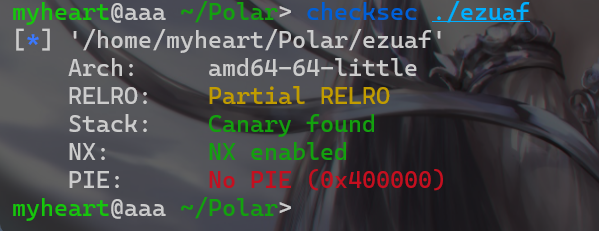
分析
- 下载附件后发现就一个附件,先来检查一下该附件的保护机制。
- 然后拖入IDA对该程序进行分析,先看到main函数,发现是一个经典的菜单题目。接下来先看看菜单
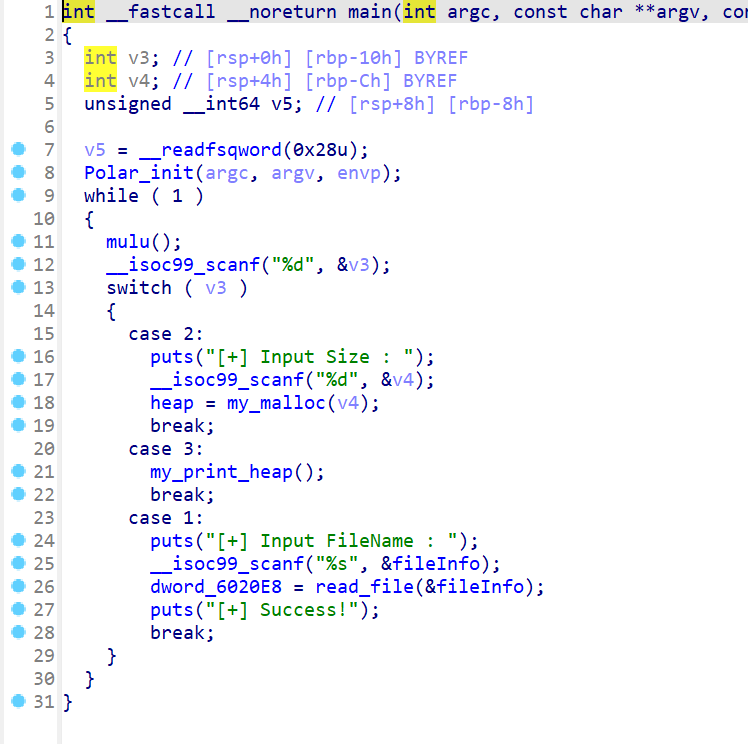
- 菜单如下,
Read是读文件,Malloc是申请堆块,Print是打印堆块内容- 主要就是看
Read函数,其他两个函数就是malloc和printf函数,基本上没啥复杂的 - 在main函数调用
Read函数之前会叫你先输入文件名
- 主要就是看
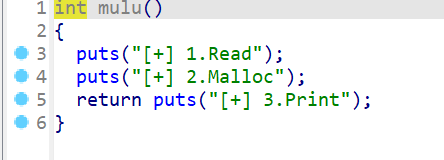
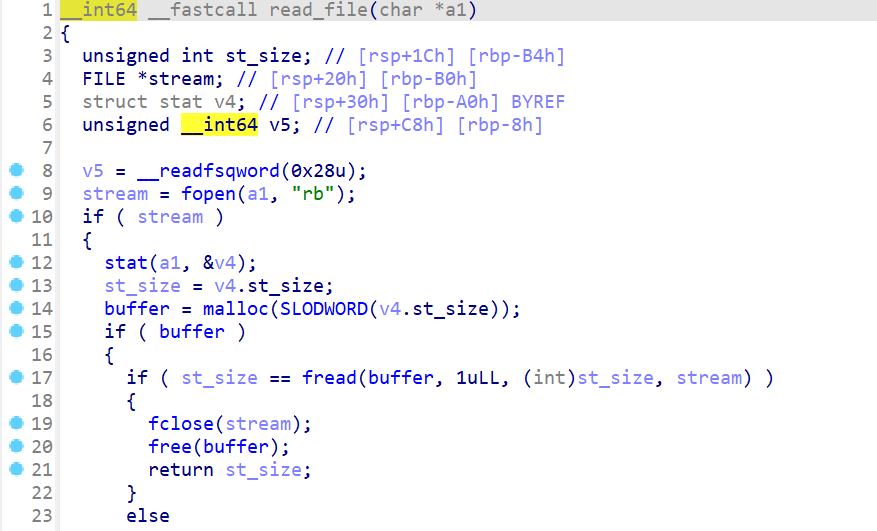
- 而
Read函数主要部分如下,剩下没有在图片上的部分都是错误处理,现在简单说一下- 先打开指定文件名的文件,然后读取文件里面的内容
- 使用malloc函数申请文件大小的堆块,将该堆块的地址存放到buffer中
- 然后再文件里面的内容存放到堆块中
- 最后释放buffer这个堆块,但是这边
free后没有把buffer置0(这里存在uaf漏洞,但是这题与uaf漏洞关系不大,主要了解堆块的运行机制)
利用
- 如果对ptmalloc堆管理器有大致了解,当申请堆块内存在一定范围内的时候,在free后空闲的堆块就会被bin管理起来。当我们再申请与之前堆块大小相同的堆后,ptmalloc堆管理器就会先检查bin,从bin找出合适的空闲堆块
- 利用这种机制,我们可以先打开
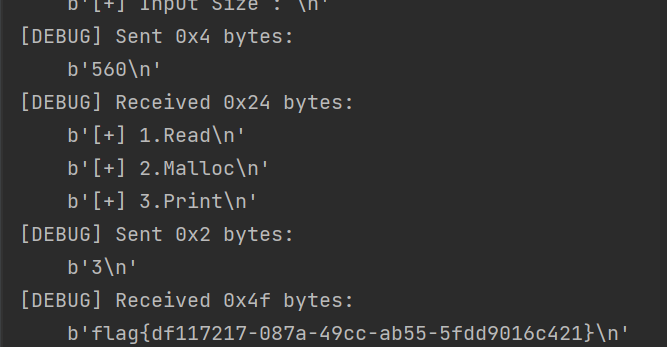
flag文件,将flag保存在堆中,然后再申请与原来文件大小相同的堆块,申请的堆块是原来被释放的堆块,此时内存数据还没被清除,这样再使用print就可以将flag的值打印出来了 - 但是这里我们并不知道要申请多大的堆块,这时我们只能对堆块的大小进行爆破
- exp:
1 | from pwn import * |
- 最后爆破出来要申请堆块的大小为
560字节
题目3–level3
- 题目来源:ctf–wiki
- 题目附件:
附加
-
对与
fast_bin的详细学习,目前都是学glibc2.23版本下的 -
fast_bin是一个数组,每个数组元素存储一个大小范围内的空闲 chunk 链表。-
fast_bin介绍不同大小的 chunk 会存储在不同的
fast_bin位置(即不同的数组元素)中。因此,一个fast_bin只能存放同一大小的 chunk。 -
数组元素数量:不论32位还是64位
fast_bin数组总共有 10 个元素。 每个fast_bin数组元素对应一种特定大小的 chunk 链表,因此,整个fast_bin数组可以存储 10 个不同大小的空闲 chunk 链表。 -
链表管理
fast_bin是一个数组,每个数组元素指向一个链表头,这个链表中的每个节点(chunk)都具有相同的大小。链表以 LIFO(Last In, First Out)的方式组织,新的 chunk 被释放时会加入链表的头部。fast_bin链表可以存放任意多的相同大小的空闲 chunk,直到系统内存耗尽或程序运行出现其他问题。 -
最小的 chunk 大小: 16 字节。
最大的 chunk 大小: 80 字节(不含 0x50 的头部大小)。
注意:这里的16字节到80字节在32位程序中的记录是不一样的,32位程序记录的有包括(chunk本身的大小和用户数据)
而64位的只包括用户使用的数据,所以在判断一个堆块是否会被放入fastbin,32位程序和64位程序是的判断机制是有区 别的
-
这里详细说明一下
-
32位对应的
fast_bin数组的大小范围为:-
fast_bin[0]:管理大小为 16 字节 的chunk(即0x20大小,包括头部)。fast_bin[1]:管理大小为 24 字节 的chunk(即0x30大小,包括头部)。fast_bin[2]:管理大小为 32 字节 的chunk(即0x40大小,包括头部)。fast_bin[3]:管理大小为 40 字节 的chunk(即0x50大小,包括头部)。fast_bin[4]:管理大小为 48 字节 的chunk(即0x60大小,包括头部)。fast_bin[5]:管理大小为 56 字节 的chunk(即0x70大小,包括头部)。fast_bin[6]:管理大小为 64 字节 的chunk(即0x80大小,包括头部)。fast_bin[7]:管理大小为 72 字节 的chunk(即0x90大小,包括头部)。fast_bin[8]:管理大小为 80 字节 的chunk(即0xA0大小,包括头部)。fast_bin[9]:管理大小为 88 字节 的chunk(即0xB0大小,包括头部)。 -
以此类推,直到
fast_bin[9],它存储 80 字节的 chunk(0x50 大小,包括头部)。 -
这里会有疑问:按照递增来说
fast_bin[9]应该是存储0x110字节的chunk,但是由于fastbin的特性,只能是存储最大的chunk为0x50
-
-
64位对应
fast_bin数组管理堆块的对应范围-
fastbin[0]:管理 16 字节的块(实际用户数据为 0 字节,最小的有效块)。fastbin[1]:管理 24 字节的块(用户数据为 8 字节)。fastbin[2]:管理 32 字节的块(用户数据为 16 字节)。fastbin[3]:管理 40 字节的块(用户数据为 24 字节)。fastbin[4]:管理 48 字节的块(用户数据为 32 字节)。fastbin[5]:管理 56 字节的块(用户数据为 40 字节)。fastbin[6]:管理 64 字节的块(用户数据为 48 字节)。fastbin[7]:管理 72 字节的块(用户数据为 56 字节)。fastbin[8]:管理 80 字节的块(用户数据为 64 字节)。fastbin[9]:管理 88 字节的块(用户数据为 72 字节)。
-
-
其他情况:
-
 wechat
wechat