参考博客:剖析 std::unordered_map O(1) 原理
- 在C++11中引入了一个容器叫做
std::unordered_map,这个容器是一个关联容器,和Python中的字典比较像,是一个键值对的数据形式。即<key,value>
介绍
std::unordered_map的实现原理是依靠哈希表来实现的。std::unordered_map是C++标准库中的一个关联容器,它根据哈希值存储键值对。std::unordered_map的模版参数包括键类型key、值类型value、哈希函数hash、键比较函数KeyEqual、和内存分配器Allocator等。unordered_map是指定类型参数具体如下:
1
2
3
4
5
6
7
| template<
class Key,
class T,
class Hash = std::hash<key>,
class KeyEqual = std::equal_to<key>,
class KeyEqual = std::allocator<std::pair<const Key, T>>
> class unordered_map;
|
unordered_map使用
定义unordered_map
1
2
3
4
5
6
| #include<iostream>
#include<unordered_map>
int main(){
std::unordered_map<std::string,int> unmap;
return 0;
}
|
- 还可以在定义的时候,对该键值对初始化一下,初始化过程如下
1
2
3
4
5
6
7
8
9
10
| #include<iostream>
#include<unordered_map>
int main(){
std::unordered_map<std::string,int> unmap{
{"文心一言",1},
{"ChatGPT" ,2},
{"讯飞星火",3}
};
return 0;
}
|
- 我们还可以在创建一个
unordered_map时指定桶的数量
1
2
3
4
5
6
| #include<iostream>
#include<unordered_map>
int main(){
std::unordered_map<std::string,int> unmap(10);
return 0;
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| #include<iostream>
#include<unordered_map>
int main(){
std::unordered_map<std::string,int> unmap{
{"文心一言",1},
{"ChatGPT" ,2},
{"讯飞星火",3}
};
for (const auto& pair:unmap){
std::cout<<"Key: "<< pair.first<<", Value: "<< pair.second<<std::endl;
}
return 0;
}
|
插入元素
- 可以使用
insert、emplace进行元素的插入,接下来逐一介绍操作
- 使用方法
insert可以插入一个键值对。例如:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| #include<iostream>
#include<unordered_map>
int main(){
std::unordered_map<std::string,int> unmap{
{"文心一言",1},
{"ChatGPT" ,2},
{"讯飞星火",3}
};
unmap.insert({"AI",4});
unmap.insert({"AAAI",5});
for (const auto& pair:unmap){
std::cout<<"Key: "<< pair.first<<", Value: "<< pair.second<<std::endl;
}
return 0;
}
|
- 还可以使用
emplace插入一个键值对,该方法允许在容器中就地构造元素,避免复制操作。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| #include<iostream>
#include<unordered_map>
int main(){
std::unordered_map<std::string,int> unmap{
{"文心一言",1},
{"ChatGPT" ,2},
{"讯飞星火",3}
};
unmap.emplace("AAA",4);
unmap.emplace("AAAA",5);
for (const auto& pair:unmap){
std::cout<<"Key: "<< pair.first<<", Value: "<< pair.second<<std::endl;
}
return 0;
}
|
查找元素
- 可以使用
find方法查找一个元素,find方法返回一个迭代器,如果找到指定的键,则返回键指向该元素的迭代器,否则返回end()。
- 所以
find()方法要接受一个键作为参数,然后返回的是一个迭代器。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| #include<iostream>
#include<unordered_map>
int main(){
std::unordered_map<std::string,int> unmap{
{"文心一言",1},
{"ChatGPT" ,2},
{"讯飞星火",3}
};
unmap.emplace("AAA",4);
unmap.emplace("AAAA",5);
for (const auto& pair:unmap){
std::cout<<"Key: "<< pair.first<<", Value: "<< pair.second<<std::endl;
}
auto it = unmap.find("AAA");
if (it != unmap.end()){
std::cout << "Found: "<< it->second << std::endl;
}
else{
std::cout<< "Not found!" << std::endl;
}
return 0;
}
|
删除元素
- 使用
clear方法可以删除unordered_map实例中的所有元素。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| #include<iostream>
#include<unordered_map>
int main(){
std::unordered_map<std::string,int> unmap{
{"文心一言",1},
{"ChatGPT" ,2},
{"讯飞星火",3}
};
unmap.emplace("AAA",4);
unmap.emplace("AAAA",5);
unmap.clear();
for (const auto& pair:unmap){
std::cout<<"Key: "<< pair.first<<", Value: "<< pair.second<<std::endl;
}
return 0;
}
|
unordered_map底层原理
-
C++中的unordered_map的实现是依靠数据结构中的哈希表hashtabel实现的。
-
数组可以通过索引index在时间复杂度O(1)下得到指定内存中元素,但是如果不知道对应的索引值,就需要O(N)的时间复杂度查找对应的索引值,再获取该索引里面的值。
-
而哈希表并没有遍历获取索引值这个缺点。哈希表的是利用如下过程来避免查找索引的。
- 定义一个键值对数据
{key,value},我们先计算key中的哈希值hashcode = hash_func(key)
- 然后再通过
模运算,使得该值在数组索引的范围内
- 这样我们就可以直接通过数组索引
a[hashcode%m]=value直接存储和获取数据
-
unordered_map就是利用这一原理。实现了时间复杂度O(1)的存取。接下来先说明一下在unordered_map中的一些名词
哈希桶数组:我们将unordered_map用于存储value的这块数组称为哈希桶数组哈希桶(buckets):是哈希表中的具体存储单元,用来存放具有相同哈希值的键值对bucket_count:用来指明哈希桶数组的长度
基本实现原理
- 我们可以通过如下过程来理解
unordered_map的存储原理,也就是上面所说的:计算key的哈希值,再对该值进行取模运算,得到的结果就是value所存储的数组索引值。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| #include<iostream>
#include<unordered_map>
size_t bucket_index(const std::unordered_map<int,int>& map,int key);
int main(){
std::unordered_map<int,int>map(5);
int key = 8;
std::cout<<bucket_index(map,key);
return 0;
}
size_t bucket_index(const std::unordered_map<int,int>& map,int key){
size_t bucket_count = map.bucket_count();
const auto& hash_func = map.hash_function();
size_t hash_code = hash_func(key);
std::cout<<"bucket_count="<< bucket_count <<"\n"<< "hash_code="<<hash_code<<"\n"<<std::endl;
return hash_code % bucket_count;
}
|
hash冲突
-
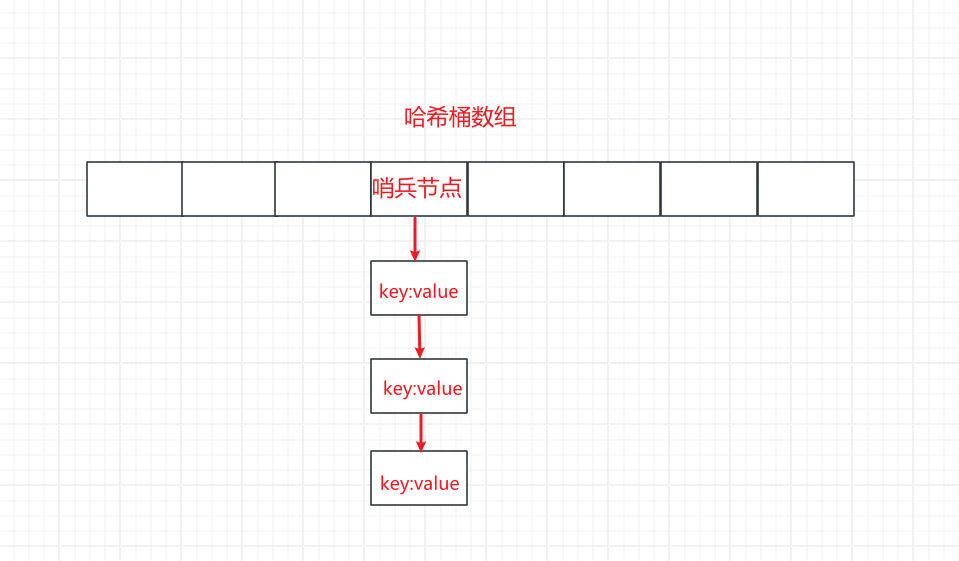
如果使用hash值+取模的这种运算就会出现一个问题,如果计算的哈希值虽然相同的可能性不大,但是经过模运算的结果相同的可能性非常大,这样就会导致同一个数组索引,存储了多个值。
-
如果遇到这种情况,我们就会把该数组索引到的地方,存储一个哨兵结点(也就是存储一个指向链表的指针),这个链表来存储模运算后结果相同的键值对。
- 这样桶的索引值,仍然是计算
key的哈希值,然后再经过模运算计算索引。
- 但是插入到索引值里面,是通过头插法插入哨兵结点所指向的链表,这样插入的时间复杂度还是
O(1)
-
这个方法叫做开链法,使用这种方法就可以解决hash冲突的问题,但是这种方法也存在一个问题。
-
当一个链表元素非常多的时候,这时我们通过链表获取键值对,就需要去链表中遍历得到相应的键值对,删除一个键值对也是一样。所以这时对该桶的操作时间复杂度就变成了O(N),hash表就退化成了链表
-
如图所示,这就是使用开链法的存储结构:
hash退化

 wechat
wechat