
vm_pwn入门
- 打算新生赛出一题
vm pwn,不知道来不来得及出。趁着出题给自己也入门一下vm pwn - 接下来介绍一下
vm pwn,这里需要纠正一个误区,vm pwn不是虚拟机逃逸之类的pwn,虚拟机的pwn可能还距离我有点远。
介绍
vmpwn一般指代在程序中实现运算指令(汇编指令)来模拟程序的运行或者在程序中自定义运算指令的程序(编译类型),这种类型的难点可能在于逆向。- 对于汇编类题型,一般的题目就像如下这样:
- 解题的关键点就是逆向出
伪汇编指令,漏洞一般就是越界读写。 - 这种类型题目的程序,一般都会让用户输入
OPCODE,之后就会将用户输入的OPCODE转换为一个伪汇编指令,通过这样来模拟程序在底层中的运行模式。
- 解题的关键点就是逆向出
- 对于
vmpwn的题目,并没有出现什么知识点,主要就是逆向;如果硬要掰扯,那么涉及到的可能就是计算机组成原理对指令设计这个理论知识点的实际应用,操作码的话如果是扩展操作码就比较难逆向,而非扩展操作码会更容易逆向。所以我们在做这题的时候就要逆向出一下几点:- 模拟的寄存器的初始值和功能,比如
SP指针,PC指针 - 模拟的内存,模拟的栈,模拟的缓冲区
- 模拟的指令,例如
mov r1,r2,r3,三寄存器运算指令,二寄存器运算指令,一寄存器运算指令,固定操作码,可扩展操作码。 - 模拟的指令规划。
- 模拟的寄存器的初始值和功能,比如
VM_PWN_level_1
- 这里由于时间原因我就哪
level_2的题目做了一个简单的修改,并且调试会变得更简单,所以这里就给出源码。
1 |
|
level_1分析1
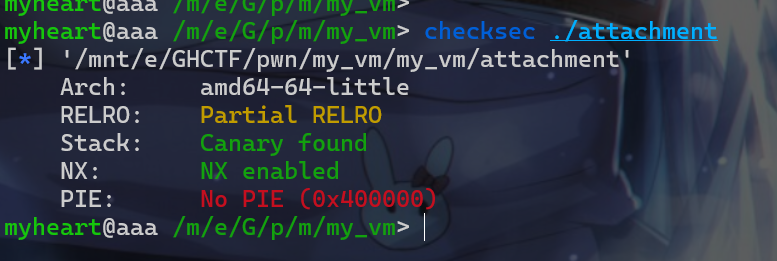
- 按照流程我们先来
check一下保护机制。发现并没有开启PIE保护
-
现在我们来反编译这个程序,查看一下这个程序的具体运行逻辑
-
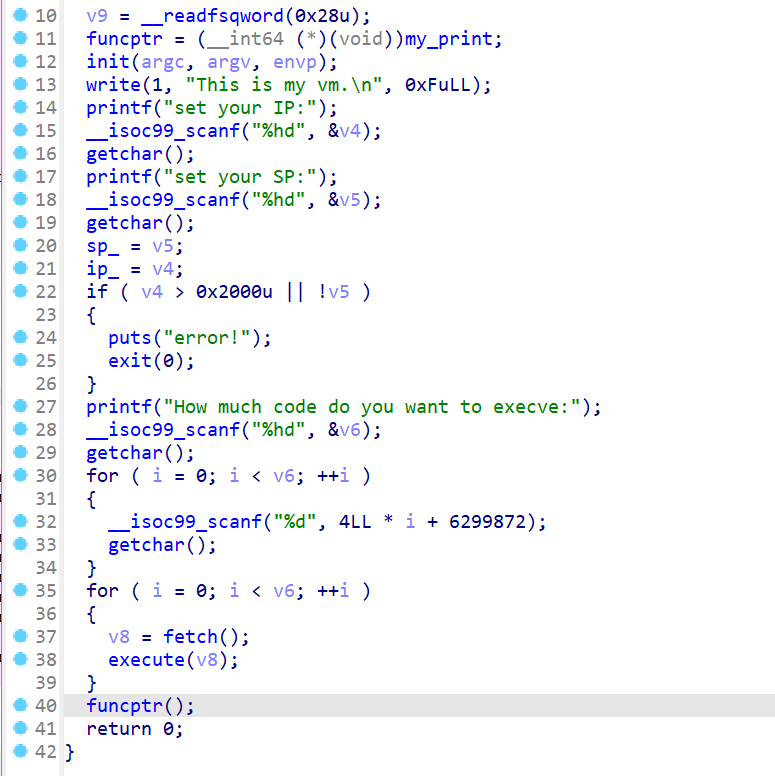
我们先来查看
main函数,我们按顺序分析这个程序- 首先会
funcptr是一个函数指针,它指向了my_print这个函数,并且使用init对输入输出进行初始化 - 然后程序会让用户输入
SP和IP,并且将用户输入的值放入sp和ip寄存器中。并检查用户输入的初始化值是否合法 - 之后程序会让用户输入程序要执行的指令数。然后进入循环,执行两个函数
- 最后调用
funcptr这个函数指针指向的函数
- 首先会
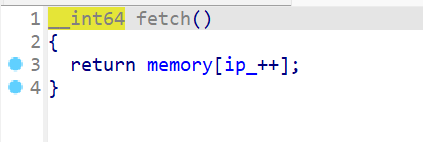
- 接下来我们查看一下
fetch()这个函数,发现就是一个取memory[ip]的值,并且将ip自增,然后返回取出来的值
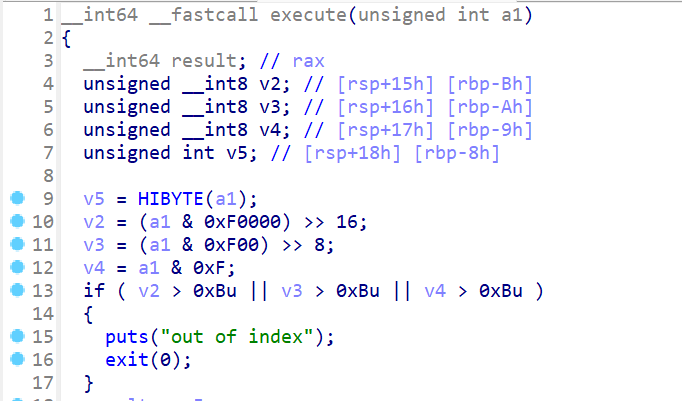
- 接下来查看一下
execute()这个函数,这个函数会将前面取出来的memory[ip]指令作为参数传递 - 这里我们一开始并不知道
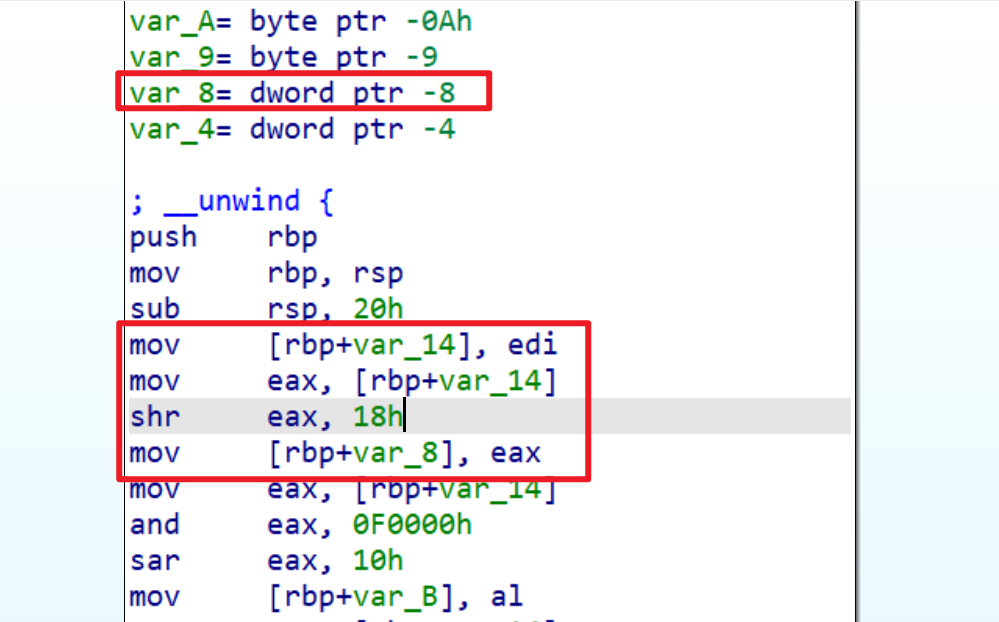
HIBYTE(a1)的值,此时我们就要查看汇编理解一下,我们先看到v5存储在rbp-8这个栈地址中 - 通过汇编我们可以看到
v5存储的是a1的最高8位,之后通过伪c代码就可以看到v2存储的值是a1的第17-20位v3存储的值是a1的第9-12位v4存储的值是a1的第1-4位
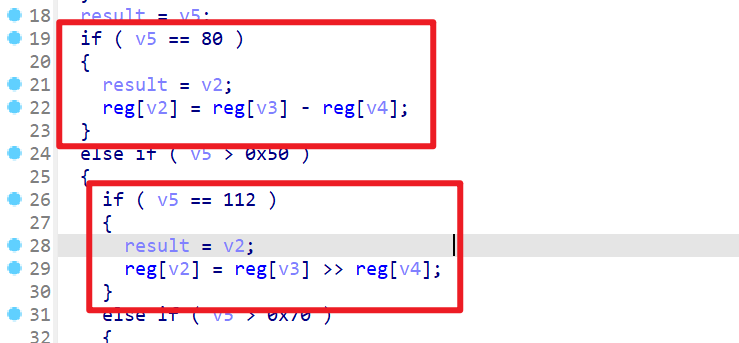
- 我们接下去查看,我们会发现当
v5即(a1的最高8位为特定的值时,会执行特定的类似于汇编指令)就像图中v5=0x50,则会执行reg[v2]=reg[v3]-reg[v4],也就是执行sub指令v5=0x70,则会执行reg[v2]=reg[v3]>>reg[v4],也就执行shr指令- 这时我们就可以知道,变量
v2、v3、v4就代表着寄存器的编号。
- 这时我们通过逆向,可以归纳出剩下的指令,而该函数模拟的指令如下,这时我们还注意到
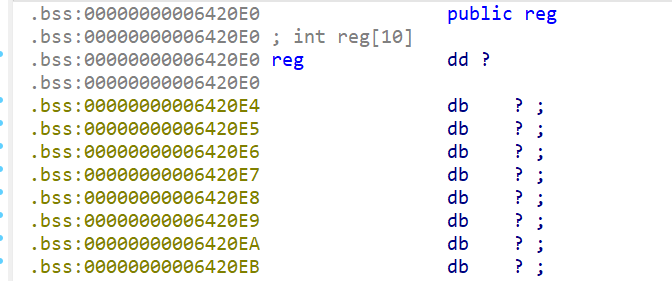
reg这个数组是int类型,而不是unsigned类型
1 | 0x10 reg[v2] = imm; mov imm |
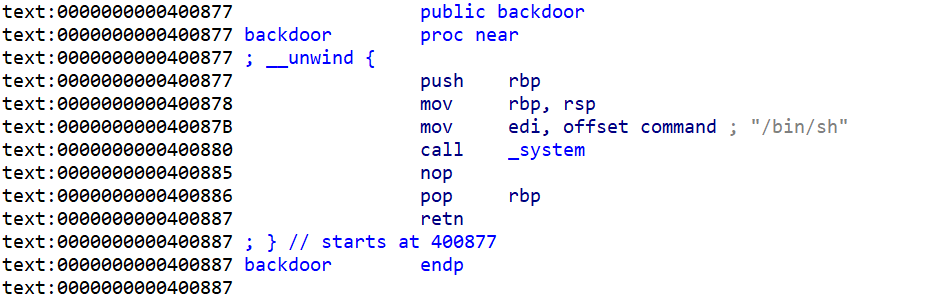
- 我们在函数这块还注意到有一个
后门函数
- 我们现在来查看一下
.bss段的全局变量,这时我们发现funcptr就在memory相邻低地址处
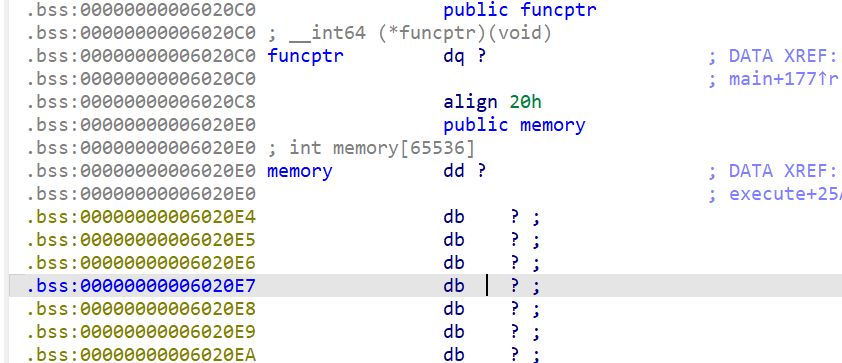
- 我们还注意到有
reg这个数组
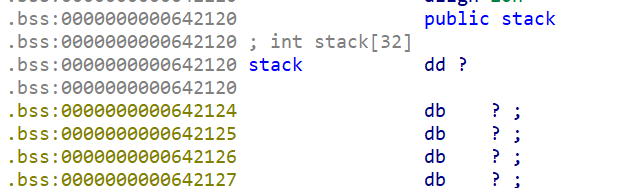
- 还注意到
stack
level_1分析2
-
这时我们可以确定漏洞点,就是利用
memory[reg[v2]]这个指令进行负索引,从而修改funcptr这个指针为backdoor()这个函数的地址。 -
接下来我们就来构造一个负索引,我们先初始化
sp=0、ip=0x1000 -
首先我们需要构造寄存器的值为负值。一开始我们的各个寄存器都为
0,我们先通过mov imm操作,将这个寄存器0、1、2赋值为8、4、20
1 | reg[0]=8 |
- 之后我们通过
0x80左移操作,将寄存器r1设置为0x400000,即:r1=r1 << r2(r1 = 4 << 20) - 然后通过
0x10这个操作将0x877赋值给r3 - 最后通过
0x40这个操作(add)将r1的值变为0x400877,这就是backdoor的地址,这一步操作就是为越界读写修改函数指针做准备
1 | reg[0]=8 |
-
之后我们要构造负索引,这时我们就用
0x50,sub指令,使r4-r0,这时我们就得到了负值。 -
最后我们再通过
0x90存指令,直接就可以实现越界读写,使得函数指针指向backdoor -
至于负索引要索引到多少,就需要动调去计算偏移了。
level_1_exp
- exp如下:
1 | from pwn import * |
VM_PWN_level_2
- 由于没有什么新知识点,那么就直接来看题,动手做一题就知道
vm_pwn的具体是怎么做的了,并且也不用害怕不理解新知识。 - 接下来就以:buuctf上的
[OGeek2019 Final]OVM作为例题来入门。
level_2分析1
- 我们拿到附件后就先来
check一下程序的保护机制。发现程序开启了如下保护机制。

- 然后我们使用
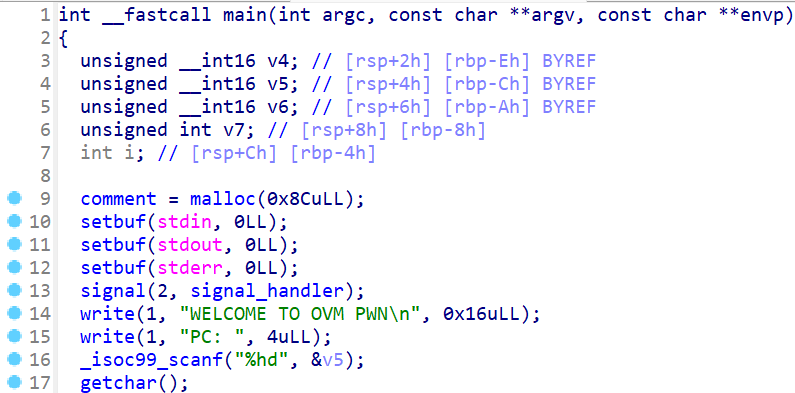
IDA对这个程序进行反汇编并且逆向出这个程序的运行逻辑。先查看main函数的执行流程,同时先运行一下这个程序,由于main函数比较长,我们根据输入点,分段逆向。- 首先程序会先申请一个堆块,然后输入输出初始化,之后会出现一个
signal函数。signal函数这里就先不管他 - 之后就会输出
WELCOME TO OVM PWN\n PC这个字符串 - 输出之后就会让用户输入一个
short int类型的数据。之后会处理用户输入的\n - 此时我们还不知道PC是什么作用
- 首先程序会先申请一个堆块,然后输入输出初始化,之后会出现一个
- 按照要求输入之后就会执行如下程序:
- 程序会输出
SP:,然后要求用户再次输入一个short int类型的数据,并处理用户输入的\n - 之后会将我们之前输入的
PC值给reg[15],会将SP的值给reg[13],(这里reg是一个拥有16个元素的数组,每个元素的数组大小为4字节) - 这下我们知道
PC的值就是程序执行的地址,而SP的值是栈顶指针。 - 这两个输入的作用就是让用户指定PC和SP的值
- 所以我们就在
IDA中加上注释,防止我们后续忘记。
- 程序会输出

- 继续接下去看代码:
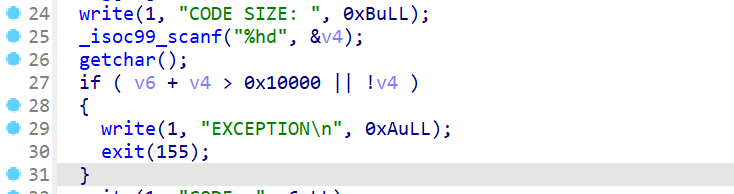
- 程序先会输出
CODE SIZE,然后再让用户输出一个short int类型的数据,并处理用户输入的\n - 之后程序会检查我们之前输入的
SP指针的值和CODE SIZE两者的和是否会大于0x1000并且检查CODE SIZE是否为0 - 如果大于
0x1000或者CODE SIZE为0,程序就会退出。
- 程序先会输出
- 接下去逆向:
- 之后程序会输出
CODE字符串,并且设置running这个全局变量为1。 - 之后会让用户循环输入
int类型的数据,循环的次数为我们之前输入的CODE SIZE。 - 所以
CODE SIZE的值就是我们之后要输入的操作数个数。 - 这里
memory也是一个全局变量,它是一个65536长度的数组,数组里面每个元素的长度为4字节。 - 并且我们
memory中的什么位置的索引开始,这与我们之前输入的PC有关。并且用户每次输入程序都会处理程序输入的\n - 注意:在用户输入后还会对用户输入的值做一个检查,即用户输入的int类型不能以0xff开头
- 之后程序会输出


- 查看最后剩下的代码:
- 程序会通过
while循环,先调用fetch()函数,将返回值给v7,之后调用execute()这个函数,并且把v7这个参数传入到execute()函数中。 - 之后用户会向
comment写入0x8c长度的内容,程序会调用sendcomment()函数,并且将comment作为参数传递进去 - 最后程序会输出
Bye\n然后结束运行。
- 程序会通过
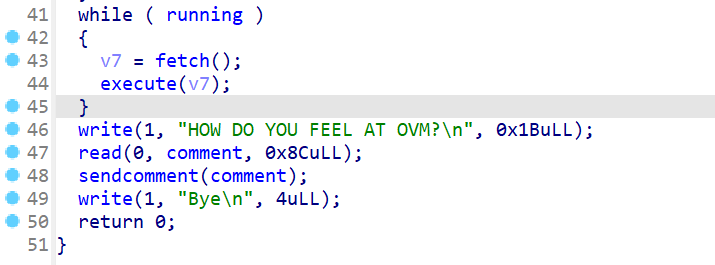
-
分析完
main函数,我们接下来就分析其他自定义的函数,主要还有fetch()、execute()、sendcomment()这三个函数。 -
接下来我们分析
fetch()函数:fetch()函数很短,就是将执行PC=PC+1这个操作- 并且返回的是
CODE的值,即下一个要执行的操作码
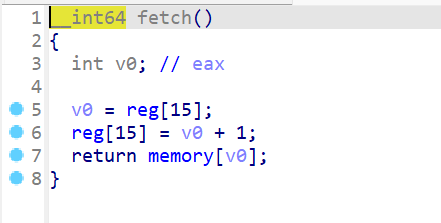
- 再来分析
execute()这个函数,这个函数的内容就非常多,所以还是需要一步一步来进行逆向,这边有很多个if分支,我们先来逐个分析:- 程序定义了
v2、v3、v4三个unsigned char类型的变量和i这一个int类型的变量 - 而
v4存储的是a1即CODE的17-20位 v3存储的是CODE的9-12位v2存储的是CODE的最低4位,- 而
HIBYTE(a1)就是取a1的最高8位(这个需要从汇编来理解)。存入rax中的最低8位,并且将rax的高位填充为0,所以指令被存储在最高a1的最高8位中 - 当
a1的25-32位的值为0x70时,就会执行if语句,也就是将执行add操作,add r1,r2,r3 <=> r1=r2+r3,并返回。 - 并且我们可以确定在三寄存器运算中
v4代表目的寄存器的编号,v2、v3都表示源寄存器的编号
- 程序定义了
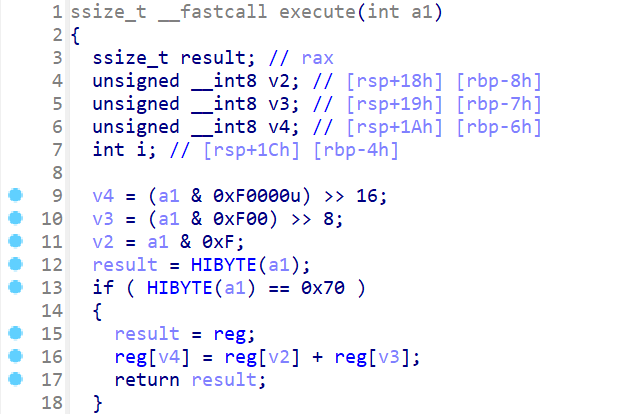
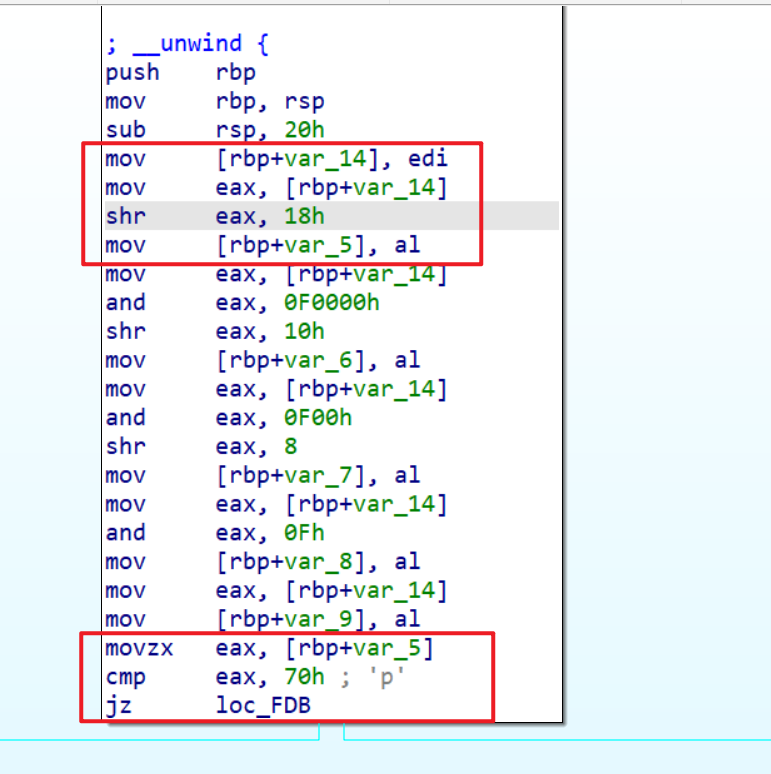
- 继续分析,接下来的
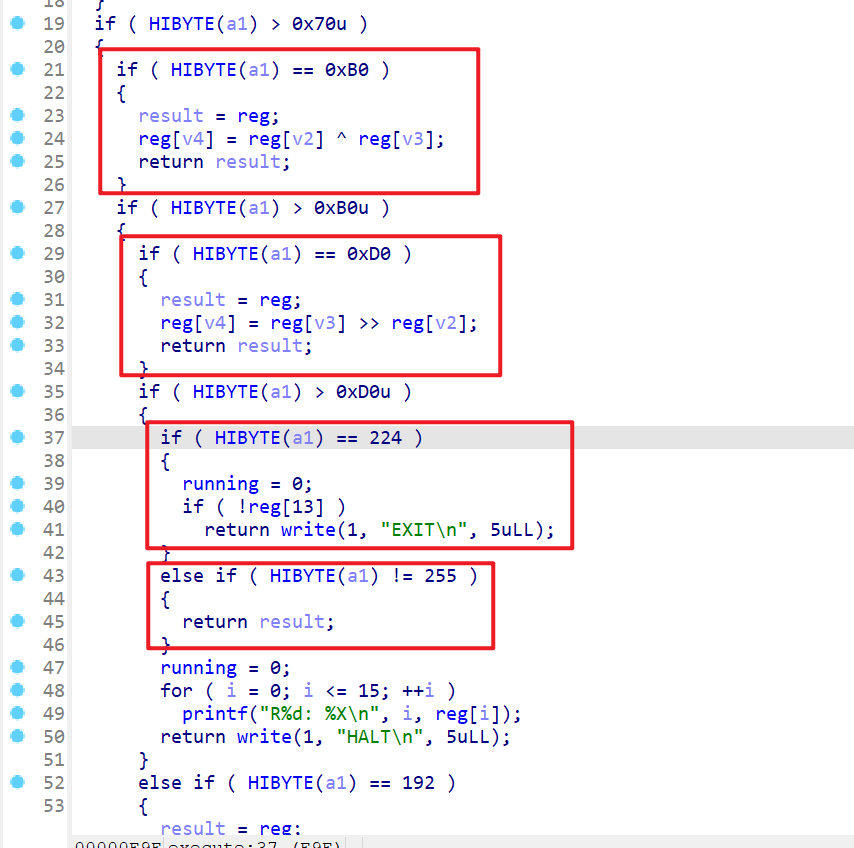
if语句稍微有点长,还是需要逐步分析,这个if语句是从第19行到第76行。- 我们先从上到下进行分析,当
a1的9-16位的值为0xB0时,执行的是寄存器的异或操作 - 当
a1的25-32位的值为0xD0时,执行的是寄存器的值位移的操作 - 当
a1的25-32位的值为224即(0xE0时),执行的是就会设置running=0也就是将要退出执行,如果reg[13]即sp寄存器的值为0还会输出退出操作。 - 当
a1的25-32位大于0xD0并且不是0xFF就会执行nop操作 - 当
a1的25-32位大于0xD0,且不等于0xFF和0xE0程序就会输出0-15这16个寄存器的值,并且会输出HALT。其实这个地方的执行逻辑并不是这样的,而是任意一个寄存器的值最高位有0xff都会输出这些寄存器的值,并退出执行。这是在后面动态调试的时候才得到的运行逻辑
- 我们先从上到下进行分析,当
- 接下来继续分析
- 当
a1的25-32位为0xC0的时候就会执行左移操作
- 当

- 之后就是如下操作
- 当
a1的25-32位为0x90时,就会进行与操作 - 当
a1的25-32位为0xA0时,就会进行或操作 - 当
a1的25-32位为0x80时,就会进行减操作
- 当

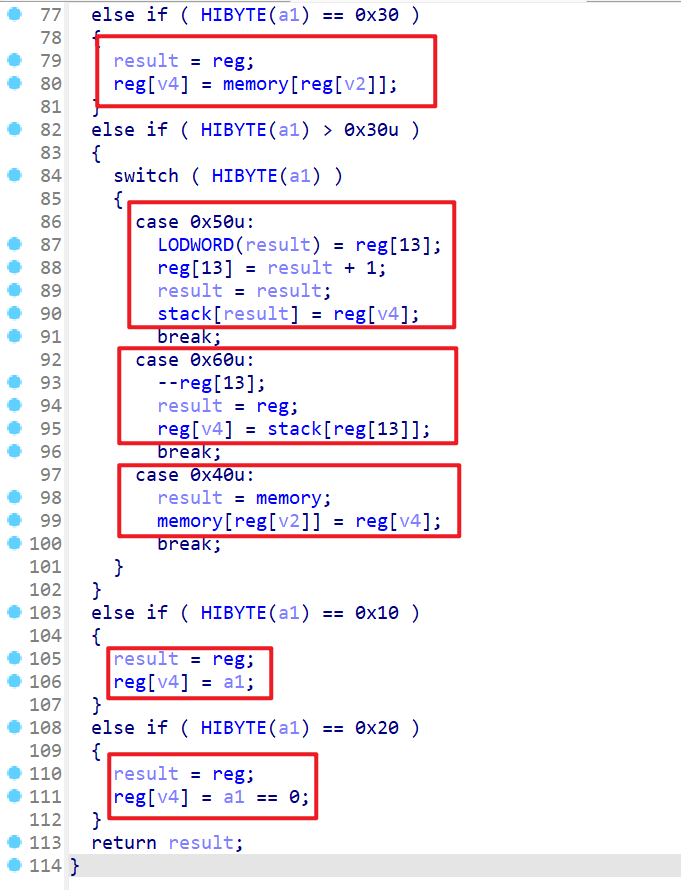
- 逆向到这里我们会注意到上面的代码就都是对寄存器的操作,而接下去的代码就是会有对内存(即全局变量
memory)进行操作。- 看到下面代码我们发现并没有使用到变量
v3,这边都是二寄存器操作或者一寄存器操作 - 从上到下依次执行的操作为当
a1的9-16位为0x30时会进行直接寻址操作,即寄存器的值被当做地址去取相应内存中的值。 - 当
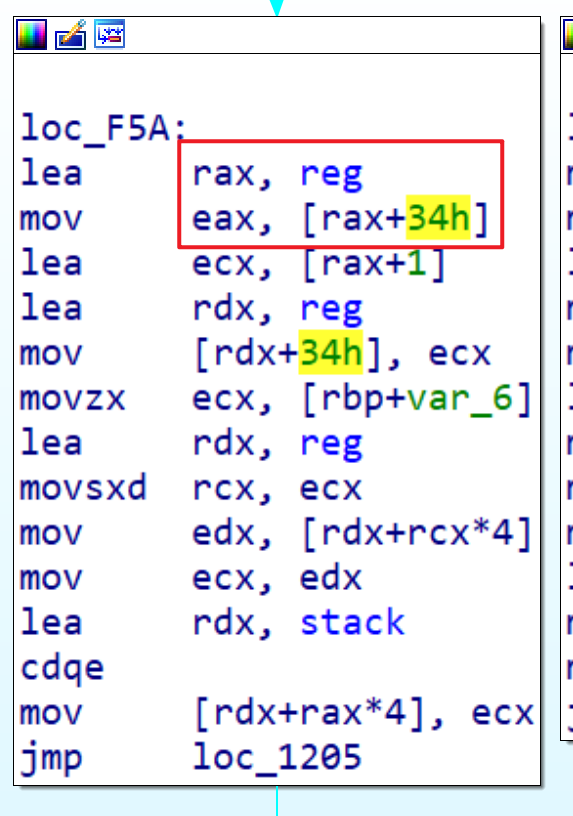
a1的25-32位为0x50时就会先将reg[13]即SP指针的值给eax,之后将SP=SP+1,然后将reg[v4]的值放入stack[eax],这个操作类似于Push,其中stack也是一个全局数组,这个数组有16个元素,并且长4字节。 - 当
a1的25-32位为0x60时就是类似于Pop的操作,Pop reg[v4] - 当
a1的25-32位为0x40时就是类似于read操作,将寄存器的值读入内存中。 - 当
a1的25-32位为0x10时,将CODE的值给指定寄存器reg[v4] - 当
a1的25-32位为0x20时,也就是相当于一个将寄存器置0的操作。 - 到此为止
execute()函数就逆向完成了
- 看到下面代码我们发现并没有使用到变量
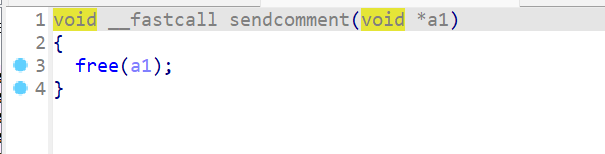
- 这时我们就开始逆向
sendcomment()这个函数,这个函数其实没什么好逆向的,就是一个free操作,但是没有将指针置0
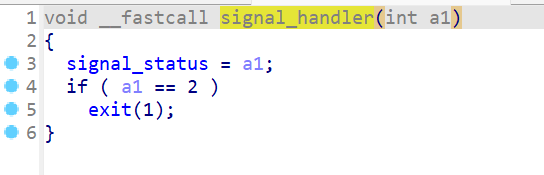
- 还有一个这个函数
signal_handler(),这个函数就是一个退出操作,锁得比较死,没什么利用空间
level_2分析2
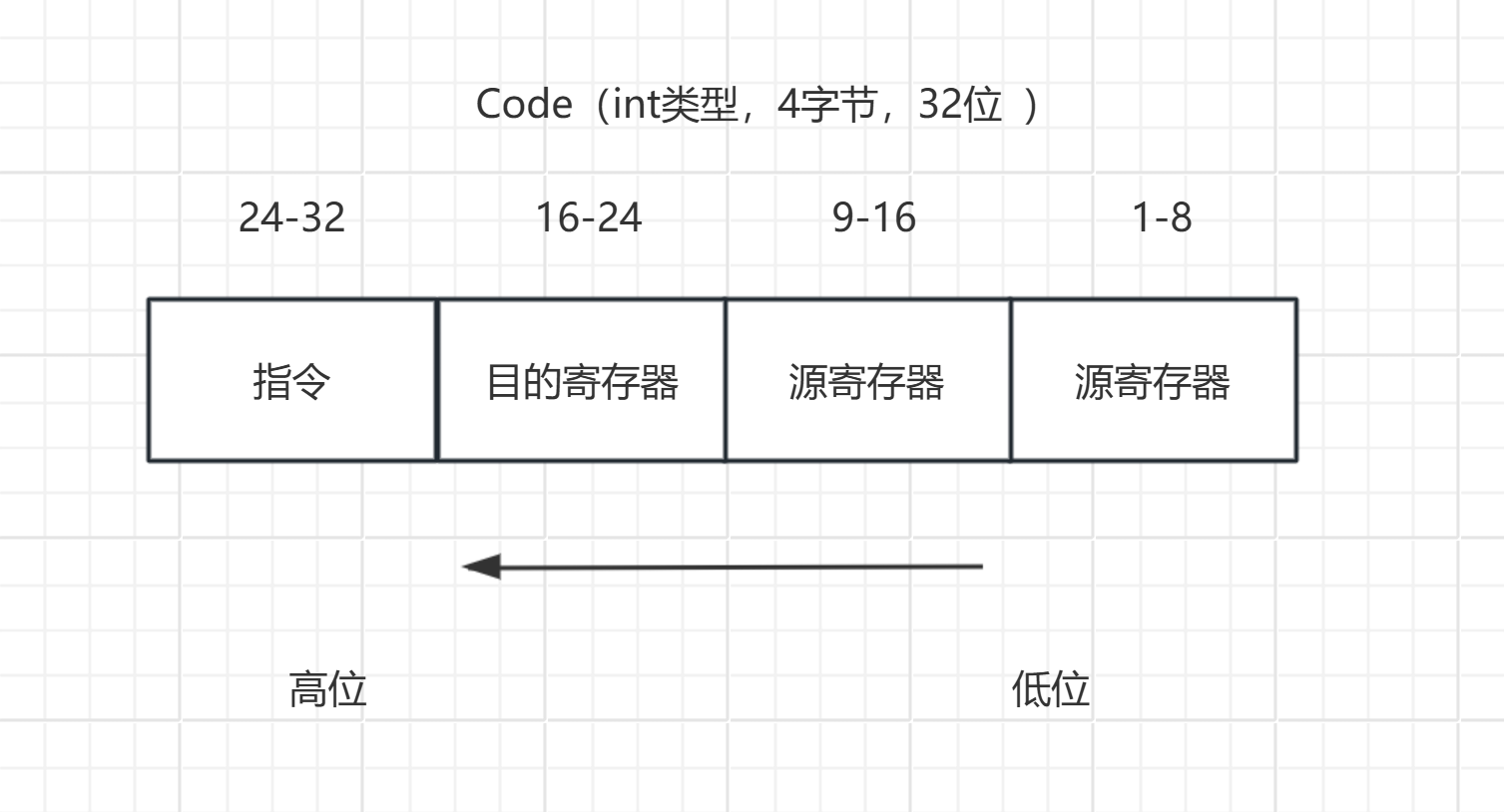
- 接下来我们就继续对指令集进行一个总结。以便我们后续进行操作。首先我们可以确定,这个操作码
CODE并不是可扩展操作码,所以这就会更好理解。 - 在上面的指令中,一般情况都是这样的形式,而且这个指令并没有进行指令扩展操作。
- 实际上,指令也就使用了高
4位,而寄存器编号也就使用了各自的低4位。 - 其中目的寄存器是变量
v4存储,9-16位的源寄存器是v3存储,1-8位的源寄存器是v2存储,且二元运算和一元运算都没有使用v3
- 然后接下来我们对汇编指令做一个汇总,并且给出初始寄存器的值:
1 | 0x10 reg[v4] = code |
- 这里我们还知道了几个全局变量,即定义在
.bss段上的变量comment存储堆块地址memory模拟内存reg模拟寄存器stack模拟栈running执行标志
- 这边我们注意到指向堆块的指针
comment是存储在.bss段中的,而我们模拟的寄存器是32位的寄存器,所以我们很可能就可以通过负索引,造成越界读写,从而修改comment的值对使其指向其他地方。 - 之后我们可以向
comment写入数据,从题目中可以得知got表不可写,所以我们这时可能就需要劫持free_hook,这里有两种劫持方式- 第一种是将
comment修改为free_hook的地址劫持free_hook,为ong_gadget - 第二种是将
comment修改为free_hook-0x8的地址处先写入/bin/sh,再写入system_addr,从而getshll - 不论是第一种还是第二种,我们都需要泄露libc地址,即将某个函数的地址打印出来,这就要使用到我们的
0xFF这个功能,而我们不能在写入code的时候写入指令0xFF,我们需要在模拟运行的时候对指令进行修改才能使得code最高一位是0xFF
- 第一种是将
- 接下来我们就边写脚本边进行动态调试,对整个程序进行分析。
- 我们先编写如下脚本,形成模版,接下来我们就着重于对
code进行编写了。
1 | from pwn import * |
- 首先我们要先进行越界读,使得我们的模拟指令能读取到内存中的
got表地址从而泄露libc的地址,我们先来查看一下memory地址与got表地址的偏移。这里我们选取泄露write的地址,首先我们计算偏移,我们发现偏移为0x1036
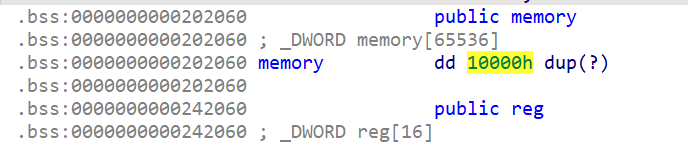
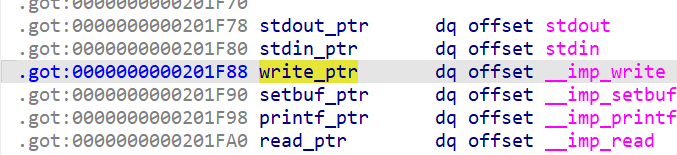

- 所以要进行越界读写,我们就首先要构造
-0x1036,转换为32位的补码为:

- 但是由于大部分寄存器的值都为
0,所以我们先要想办法使得某个寄存器的值为FFFF EFCA,我们先通过:0x10000000:即reg[v4] = code,这样就可以进行操作,使得reg[0]=0x100000000x50000000:即push reg[0]0x10000001:即reg[0] = 0x100000010x60010000:即pop reg[1]0x80000001:即sub reg[0]=reg[0]-reg[1],从而得到数据1。
- 由动态调试会发现寄存器的值如下:
1 | reg[0]=1 |
- 这时我们使用
add命令,将reg[1]寄存器也变成1,再使用add命令将reg[1]变成2,之后使用左移命令,将reg[2]变成4,使用add命令使得reg[3]变成8,再使用add命令让reg[4]变成16。 - 此时继续动态调试得到,寄存器的布局如下:
1 | reg[0]=1 |
- 这时我们可以使用
<<命令,先将使得reg[5] = reg[0] << reg[3],再使得reg[5] = reg[5] << reg[2],这样就可以构造出数据0x1000,然后使用add命令,加上三次0x10、一次0x2、一次0x4即可得到0x1036
1 | reg[0]=1 |
- 这时我们使用
sub命令就可以构造出负值,从而得到负索引,但是在得到负索引之后,发现一个问题,程序会直接输出所有寄存器的值,然后让用户输入内容,这并不是我们所期望的。

- 所以我们不能使用
sub去构造负值,我们现在来试试一下使用位移和加法操作是否可以构造出负值。我们现在就利用sub命令使得reg[6]=reg[4]-reg[0],然后再使用4次位移操作,得到最高位F和第二高位F,然后再通过add命令,看看是可以不触发输出寄存器的值。 - 到目前为止,我们的代码如下:
1 | from pwn import * |
- 寄存器的值如下:
1 | reg[0]=1 |
- 这时我们再使用
add命令,构造出最高位的0xff,但是还是会触发输出寄存器的值,从而退出执行。所以之前逆向的逻辑就有错误。
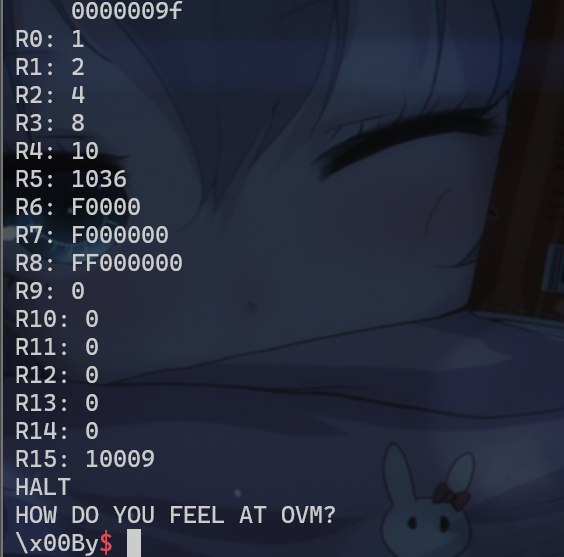
level_2_exp
VM_PWN出题
-
如果我们要出一道
VMpwn题,即制作一个简单的VM,我们的程序至少要有如下东西:- 需要准备
寄存器和栈内存,用于数值的传递 - 如果要输出
字符串还需要有一个缓冲区BUFFER
- 需要准备
-
VMpwn题中常见的设计如下:- 初始化分配模拟寄存器空间(即分配内存空间,将这个内存空间当做寄存器,可以是变量或者是其他可读可写的内存空间)
- 初始化分配模拟栈空间(STACK)
- 初始化分配模拟数据存储空间(BUFFER)
- 初始化分配存储OPCODE(机器指令)空间
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 iyheart的博客!
 wechat
wechat