
ret2dl-resolve
- 最近经常做到
only_read类型的题目,这种类型的题目我都是使用SROP做的非常麻烦。而这种题型ret2dlresolve的利用就变得非常方便。 - 注:没有特别说明,调试环境和题目环境都是在
glibc2.23下进行的 - 参考博客:ret2dlresolve超详细教程(x86&x64)-CSDN博客
前置知识
- 在
ret2libc中我们已经初步了解了plt和got这两个表,我们泄露libc的地址都是通过got表来泄露的,并且已经稍微了解延迟绑定技术。并且泄露的时候我们需要找已经被调用过一次的库函数的got表地址,这样我才能泄露出libc的地址,否则泄露的并不是libc的地址 - 因为
Linux中的延迟绑定机制导致了函数在没调用之前是不会写入libc的地址到got表的。而在第一次调用的库函数的时候,并不是直接跳转到libc中相应的地址去执行相关函数,而是先会执行一个名为_dl_runtime_resolve(link_map,reloc_arg)的函数。先将函数的libc地址写入到got表后,程序才会真正的调用函数。 - 而
ret2dlresolve其实就是通过溢出等手段,控制调用函数_dl_runtime_resolve(link_map,reloc_arg)时传入的参数,以及伪造传入参数对应的地址里面的内容。
延迟绑定机制(Lazy Blinding)
-
主要了解一下延迟绑定机制的主要过程,在了解过程之前我们要先了解一下
plt表和got表的具体结构。 -
我们以这个代码为例子:
1 |
|
GOT表结构
-
为了有利于了解过程,先要了解一下这俩个表的结构。
-
先来了解一下
got表的结构,got表其实就是一个指针数组,got表里面存储的全部是地址。对于上面编译好的示例程序,先使用IDA pro反编译查看一下got表。 -
如下图所示:
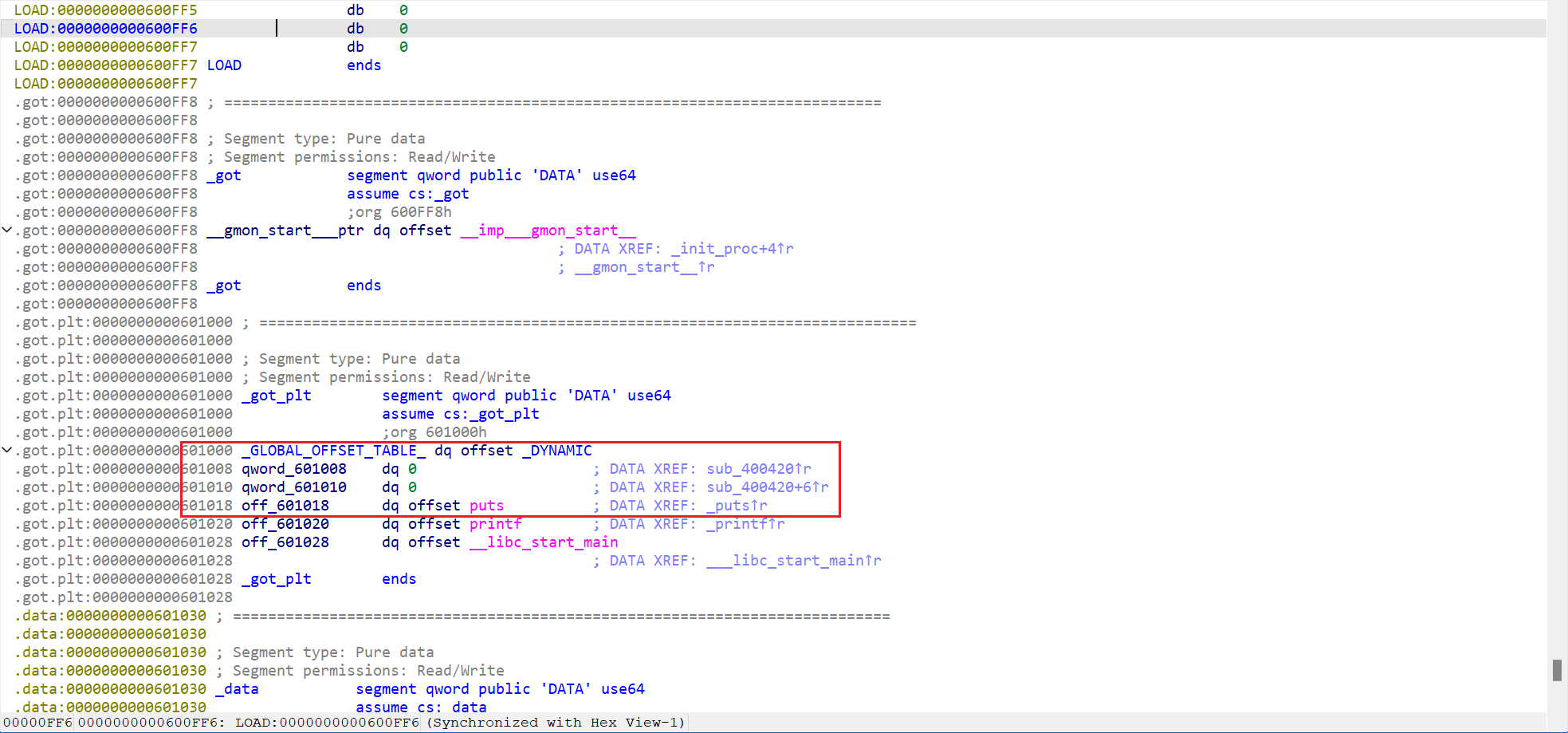
- 发现
got表其实有俩个节,其中一个是.got,另一个其实是.got.plt。对于第一个.got主要是用于重定位,而不是延迟绑定,在延迟绑定所说的GOT表其实指的是.got.plt这个节。 - 并且还发现
offset puts是被放在了got[3]这边,前面还有got[0]、got[1]、got[2] got[0]是指向_DYAMIC所在的位置,而_DYAMIC其实是.dynamic的结构,但是got[1]、got[2]都被设置成了0
- 发现
- 动态调试看一看
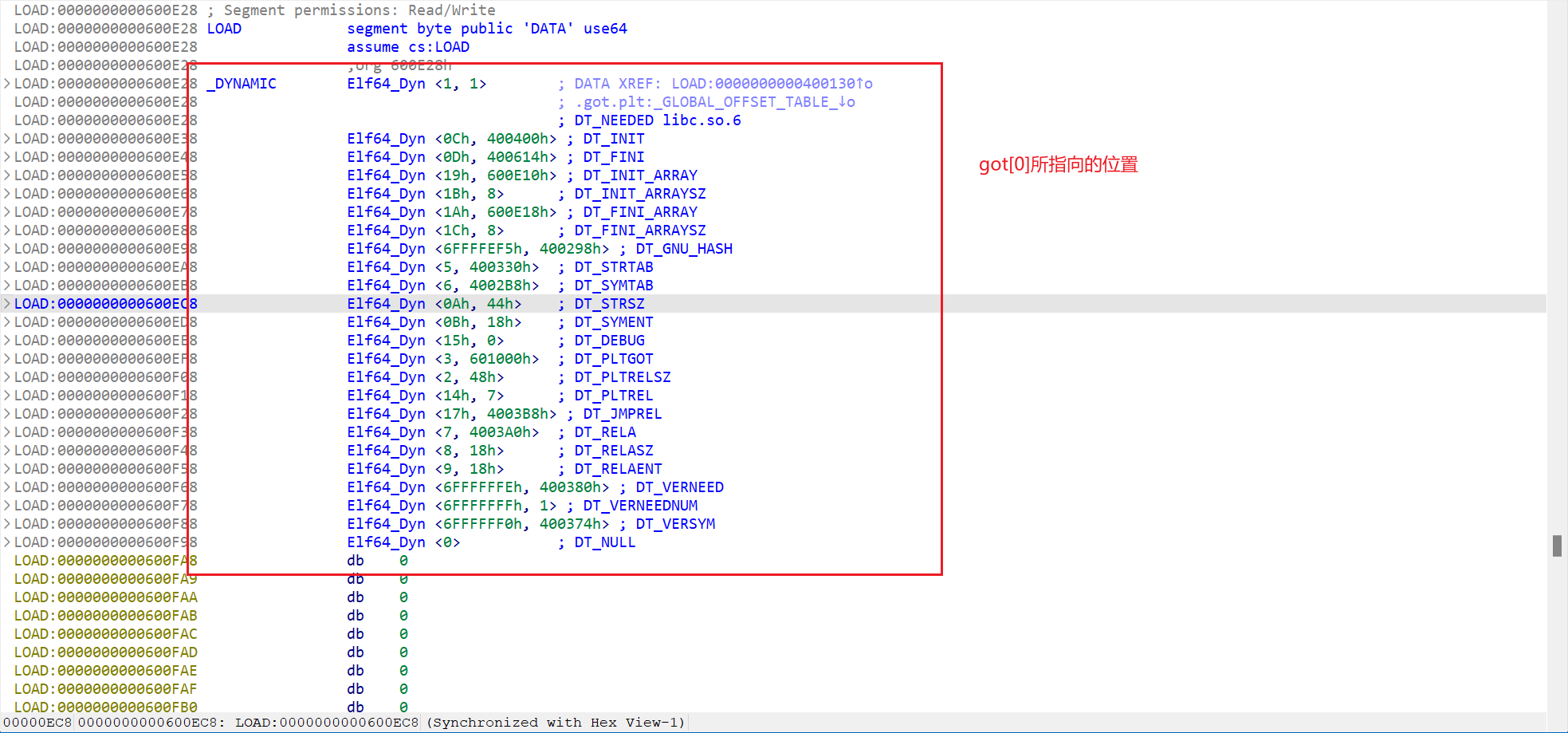
got[1]、got[2]发现有值存在,而这个值是在程序一开始运行时写入进去的,而不是在编译的时候写入进去的。 - 并且
got[1]存放的其实是link_map *这个指针,got[2]存放的就是_dl_runtime_resolve这个函数的地址。
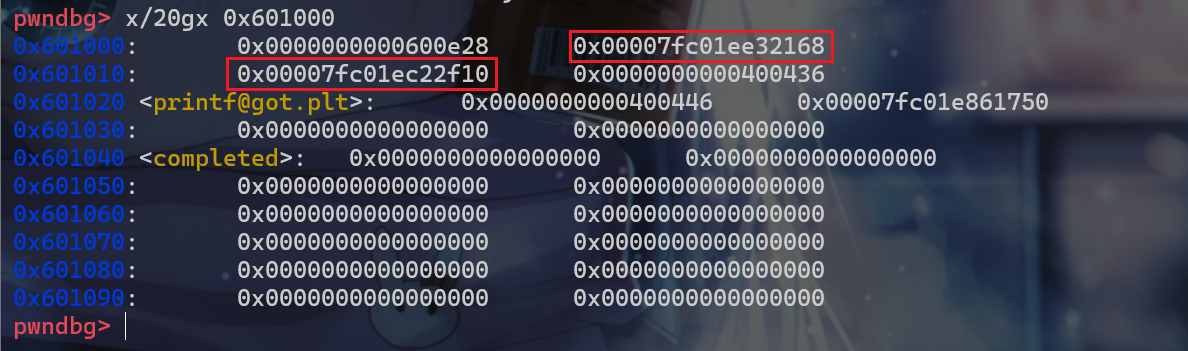
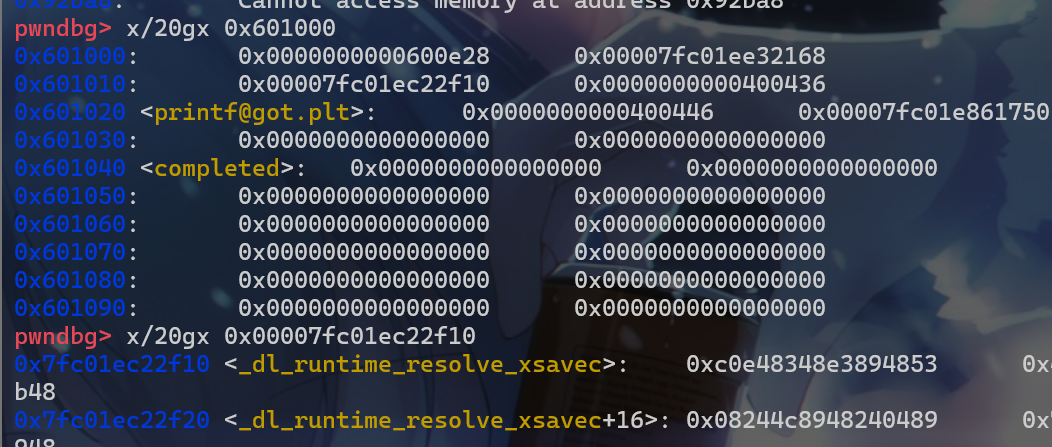
- 这样一来就可以知道
got表的大致结构了。

PLT表结构
- 接着在IDA中查看一下
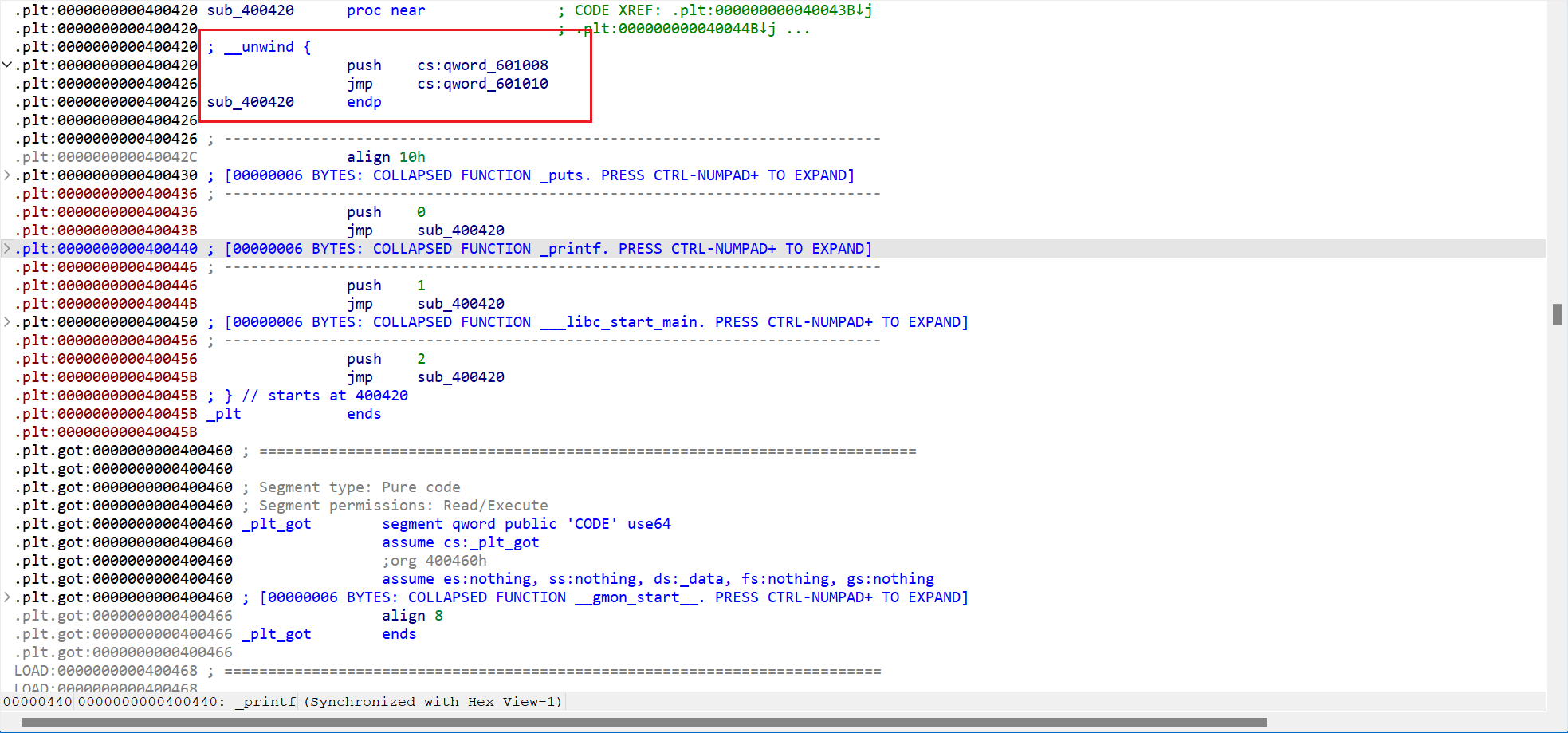
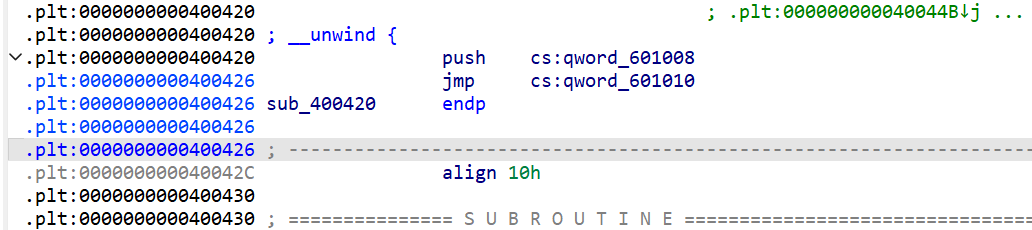
PLT表的结构:- 这里也发现有
.plt表和.plt.got表,询问AI发现是这样,老版本的延迟绑定是将延迟绑定函数1@plt和调用_dl_runtime_resolve的那段汇编和在一起(即图中红框)。新版本是新增一个跳板即.plt.got这个地方存放的是__cxa_finalize@plt。这里先了解一下,新版本之后介绍。 - 点击
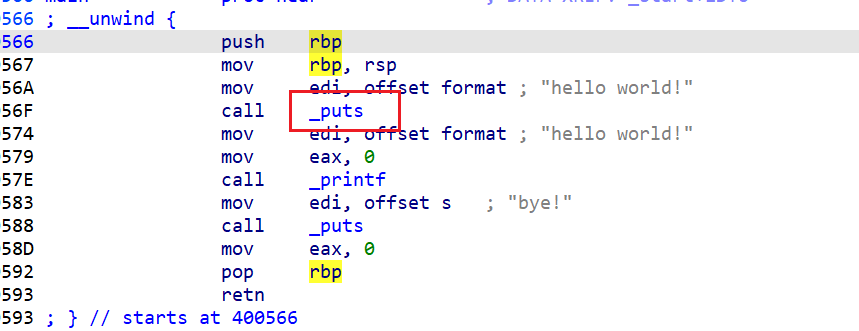
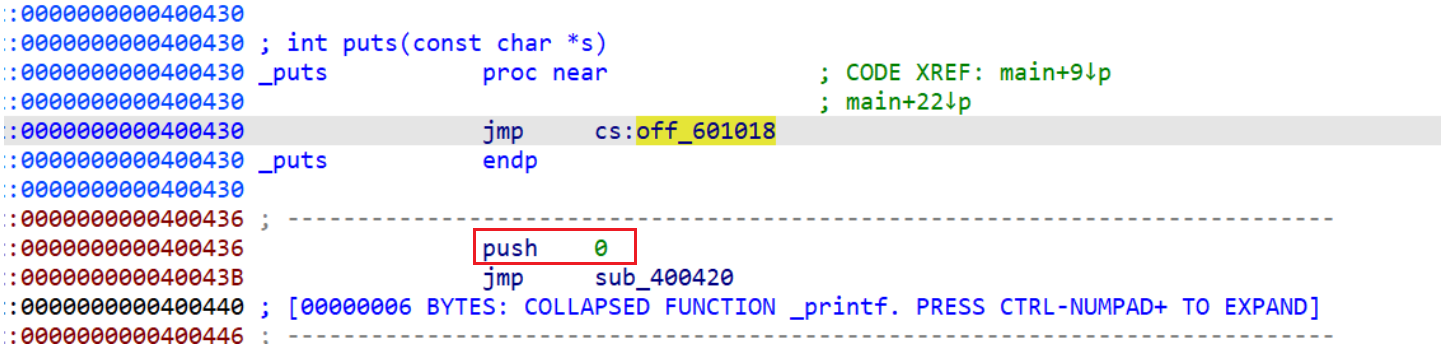
_puts后会跳转到_puts@plt,之后又会执行一个jump其实就是jump到puts@got一开始存储的值,即_puts@plt+6
- 这里也发现有
- 这里其实
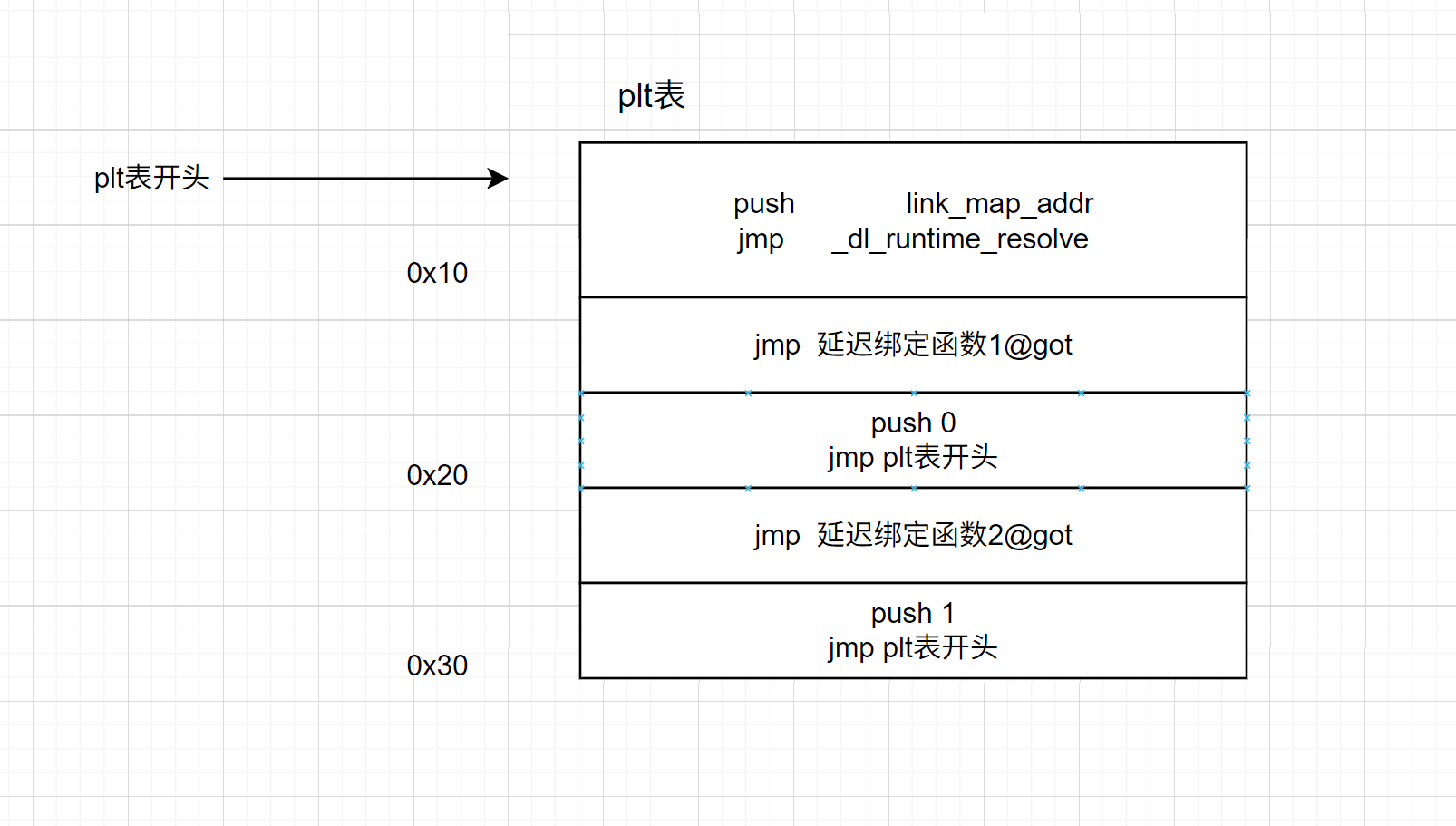
plt表的结构比较清晰:
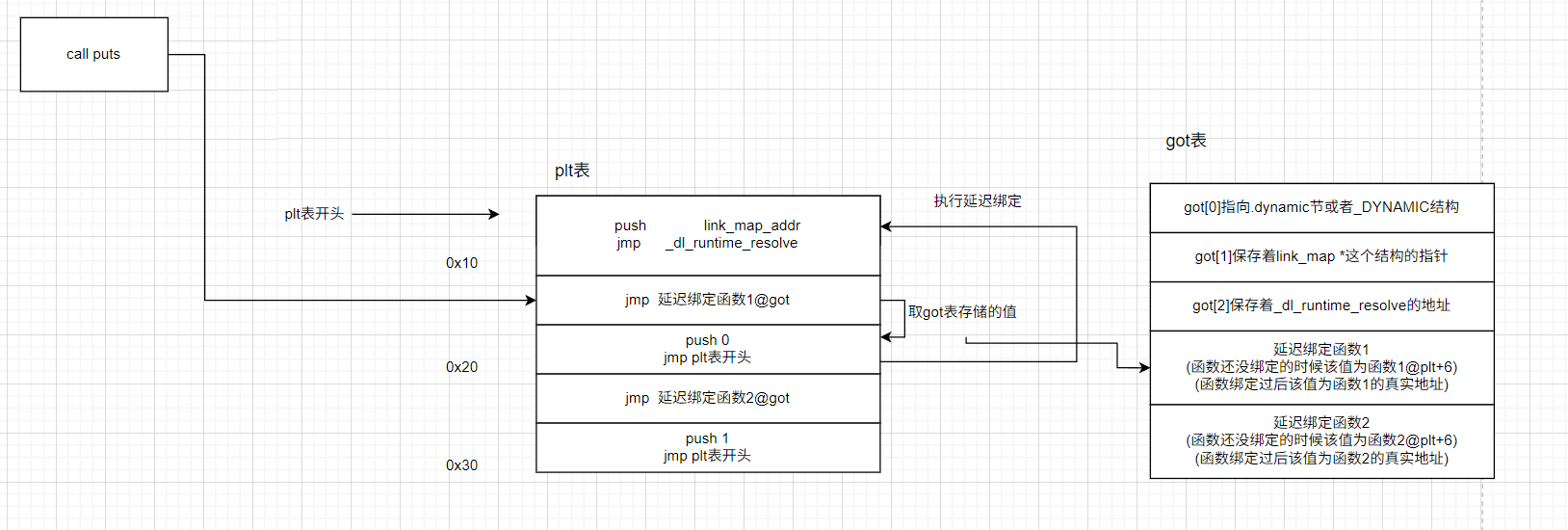
延迟绑定流程
- 我们先来调试一下,先了解一延迟绑定的流程。首先是第一次调用
puts函数,call puts@plt。
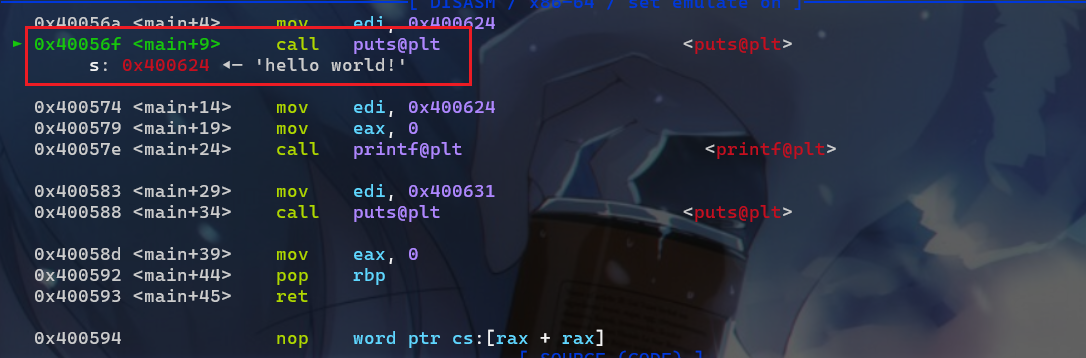
- 接下来就执行
puts@plt表存储的指令也就是jmp got[3]。注意:这里是jmp到got表存储的地址,而不是jmp到got表,这里got[3]=puts@plt+6
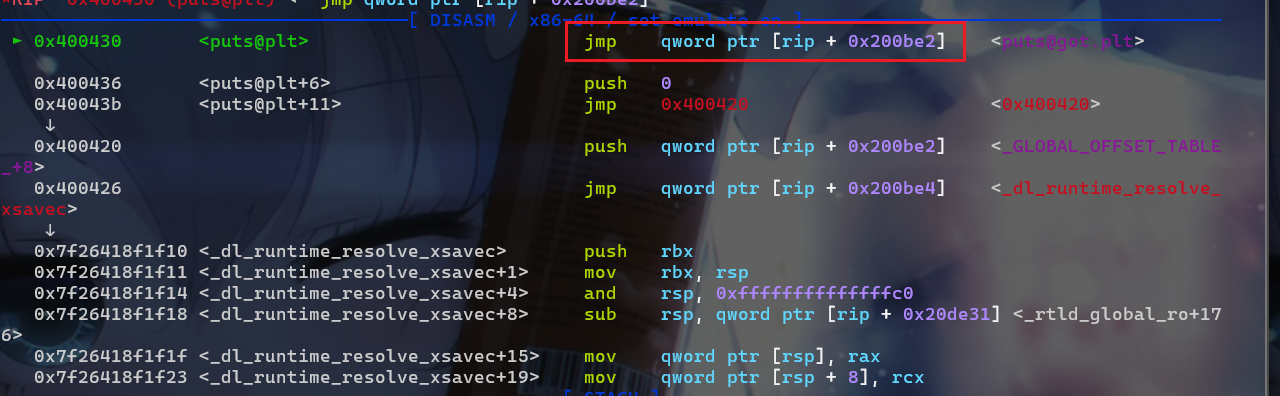
- 然后就会执行
puts@plt+6位置的指令push 0; jmp 0x400420
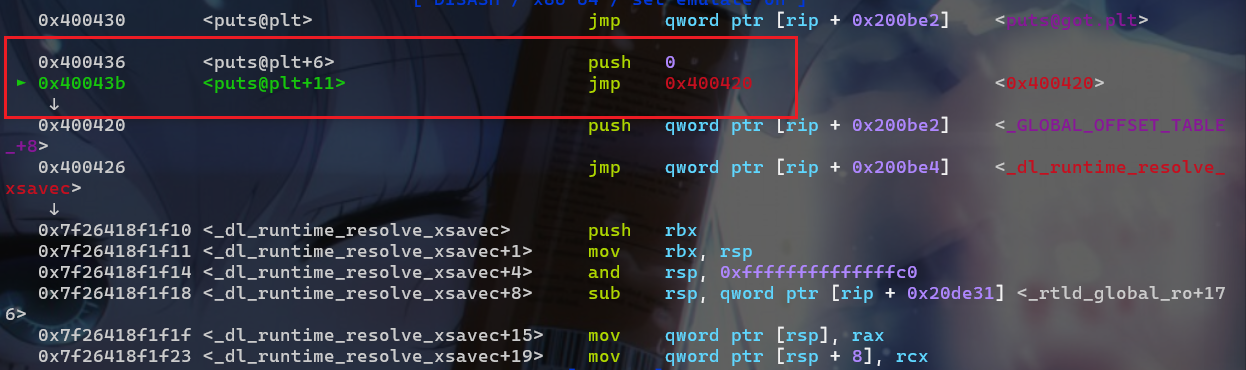
- 此时又跳转到
plt表的起始位置去执行这段汇编

- 之后就跳转到
got[2]存储的位置,也就是_dl_runtime_resolve_xsavec函数,执行完之后puts@got中存储的就是puts函数的真实地址了。
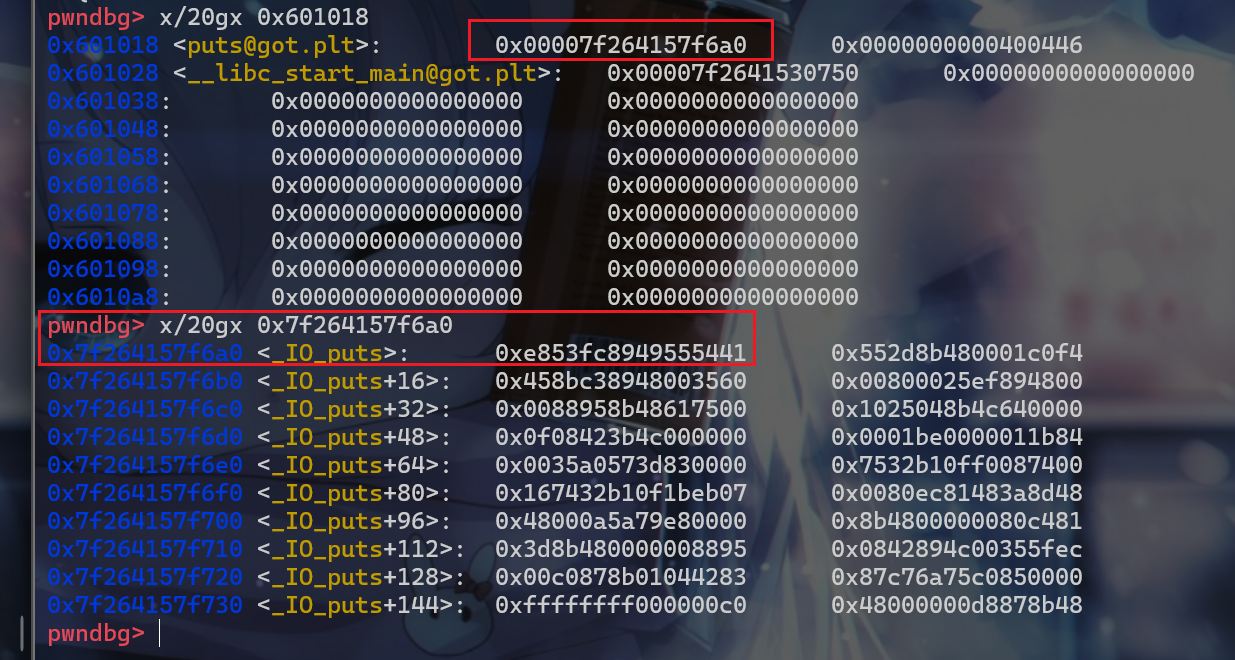
- 接下来简述一下流程:
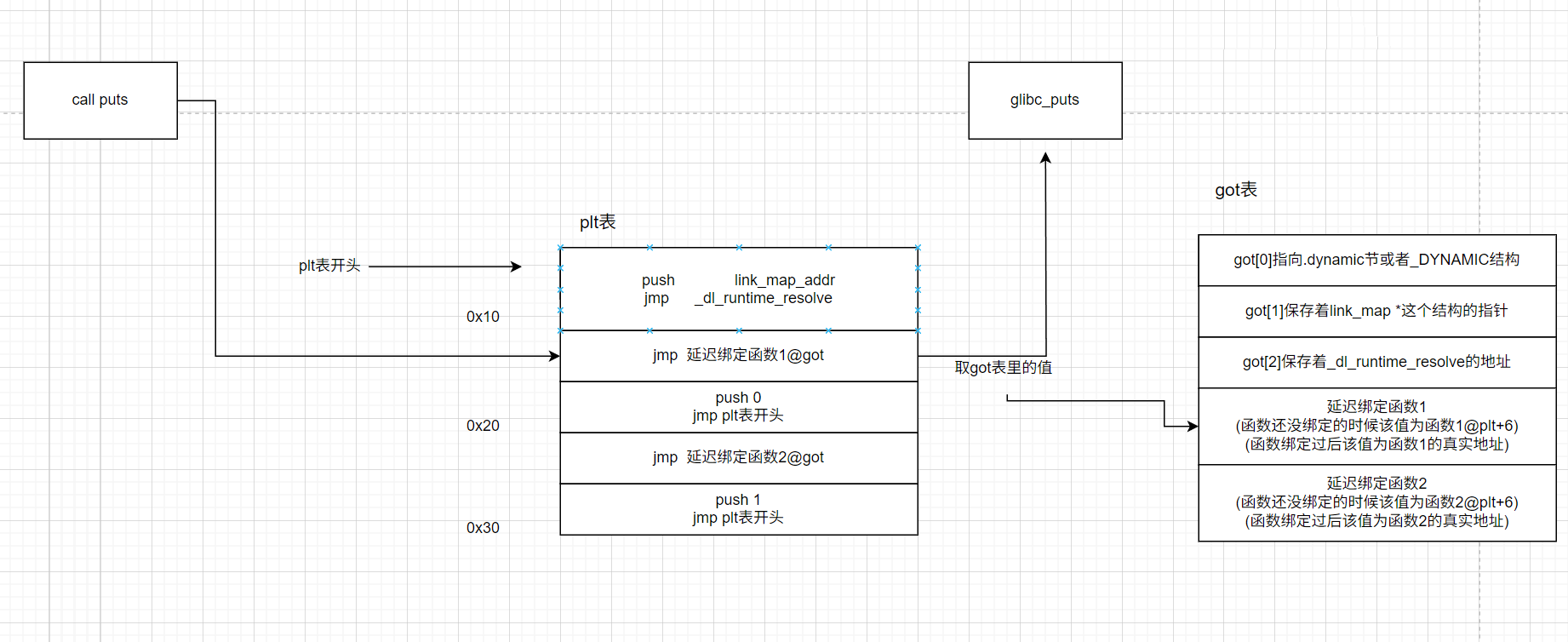
- 当第二次调用的时候:
_dl_runtime_resolve执行流程
- 了解完延迟绑定机制后,现在了解一下
_dl_runtime_resolve这个函数的执行流程。直接查看源码,在glibc/sysdeps/x86_64/dl-trampoline.h这个文件下,但是这个函数并不是延迟绑定最重要的一个函数。
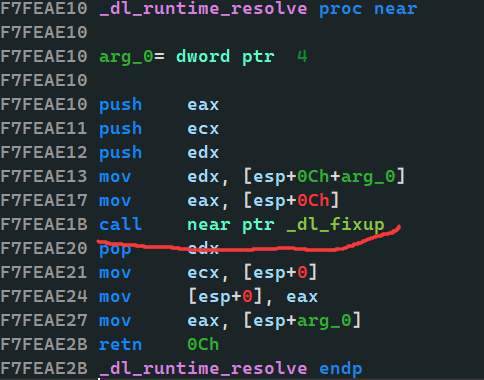
_dl_fixup
- 在
_dl_runtime_resolve它会调用_dl_fixup这个函数,此处借一张图
1 | _dl_fixup(struct link_map *1,ElfW(Word) reloc_arg) |
- 所以其实延迟绑定的最主要的函数是
_dl_fixup这个函数,接下来查看一下这个函数的源码,在文件夹glibc-2.23/elf/dl-runtime.c中实现的
1 | _dl_fixup ( |
- 其中
_dl_fixup会调用如下几个函数
1 | _dl_fixup |
传入参数
- 在调用
_dl_fixup的时候会传入俩个参数,分别为link_map *l和Elfw(Word) reloc_arg,深入了解以下这俩个参数。
1 | _dl_fixup(struct link_map *1,ElfW(Word) reloc_arg) |
- 在正常的延迟绑定时,
link_map* l其实就来自got[1]

- 而
reloc_arg(重定位表索引)
- 这里重点介绍一下
link_map这个结构体,在glibc-2.23/elf/link.h中可以找到
1 | struct link_map |
ElfW(Dyn) *l_ld这个地址其实就是在IDA中的这个位置,其实也就是got[0]的位置

- 而
ElfW(Dyn) *l_ld这个段内存地址保存着很多下面这样的结构体。
1 | typedef struct |
重要过程与结构体
- 接下来就是
ret2dl-resolve的关键点
1 | _dl_fixup(struct link_map *l,ElfW(Word) reloc_arg) |
- 首先是这个语句
1 | const PLTREL *const reloc = (const void *)(D_PTR(l, l_info[DT_JMPREL]) + reloc_offset); |
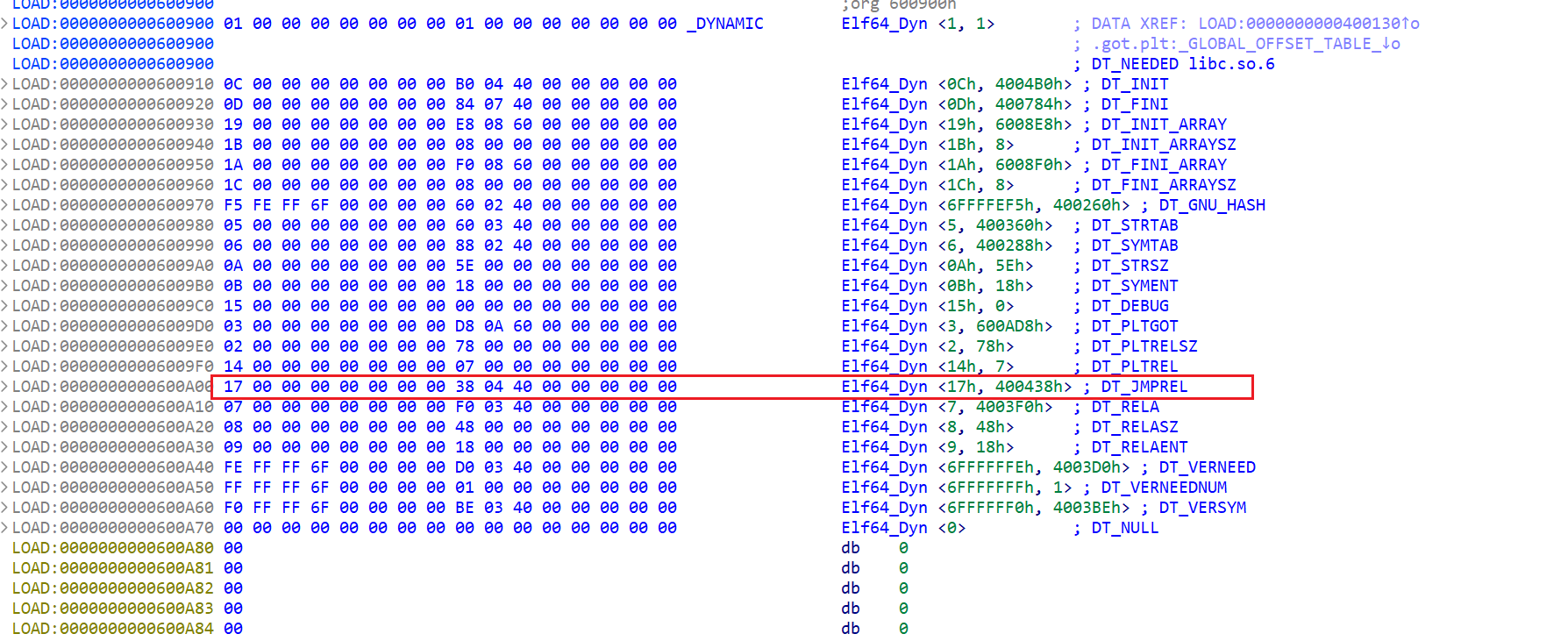

- 接下来这一句
1 | typedef struct |
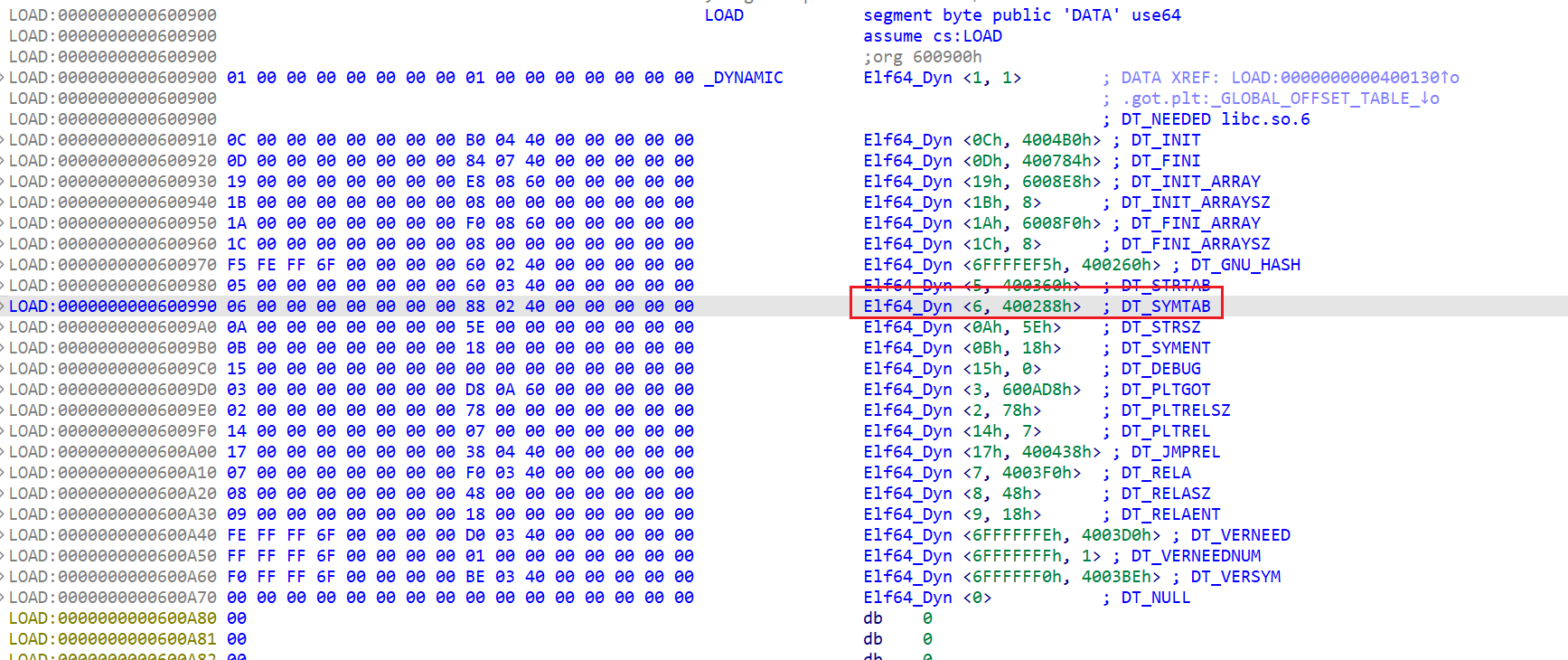
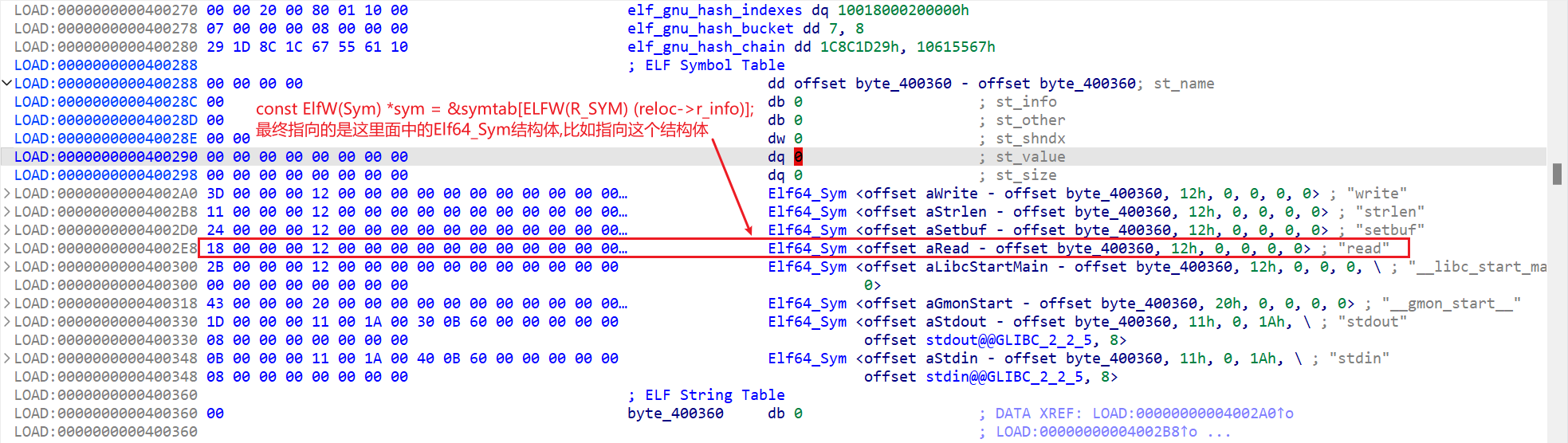
- 接下来是做判断的,这里稍微注意一下即可
1 | assert(ELF(R_TYPE)(reloc->info) == ELF_MACHINE_JMP_SLOT); |
- 接下来
1 | // 接着通过strtab+sym->st_name找到符号表字符串,result为具体函数的地址 |
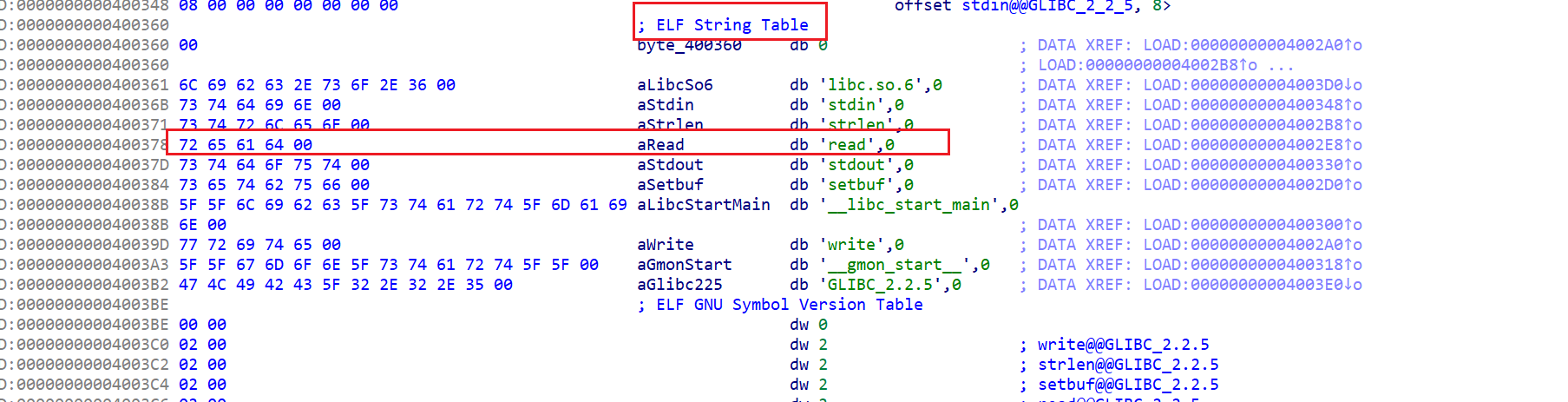
- 最后
1 | //计算符号的最终重定位值 |
总结
- 经过对重要过程的分析,一般我们要利用
ret2dl-resolve有如下几种思路:- 能利用的有
_dl_fixup(struct link_map *1,ElfW(Word) reloc_arg)中的reloc_arg - 还可以
伪造某些结构体,或者修改某些结构体的值+伪造结构体 - 伪造
link_map这个结构体
- 能利用的有
ret2dl-resolve
- 注意:如果开启了
FULL_RELERO就没办法利用ret2dl-resolve,因为FULL_RELERO会使得程序在执行前将这些库函数地址给解析完毕,因此got表中got[1]和got[2]中存储的值并不会被使用,所以GOT表中的这俩个地址均为0。 - 其实
ret2dl-resolve的基本思路就是我们通过栈溢出,先伪造出调用_dl_runtime_resolve需要传入的结构体,然后由攻击者调用_dl_runtime_resolve函数,从而修改指定函数的got表为system函数,最终达到getshell。
64位程序的利用
NO RELRO情况例题
1 |
|
- 先来分析一下程序,
main函数先输出Welcome to XDCTF2015~!,然后再进入vuln函数
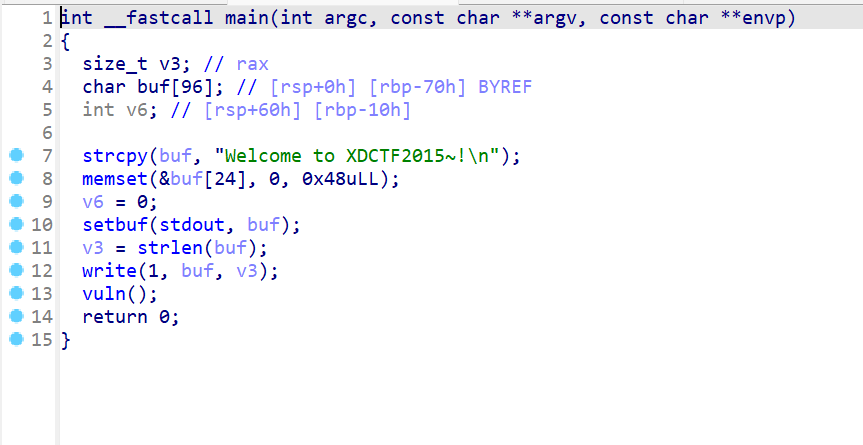
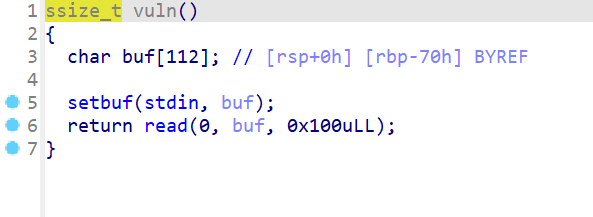
- 之后查看
vuln函数,这里存在栈溢出。
- 这题我们就采用
修改某些结构体的值+伪造结构体,基本思路就是劫持Elf64_Dyn中的d_un成员,劫持到我们伪造的Str_tabel中,然后使用ret调用_dl_runtime_resolve对某个got表重新绑定,绑定成system函数的地址,之后再调用即可system("/bin/sh")
1 | typedef struct |
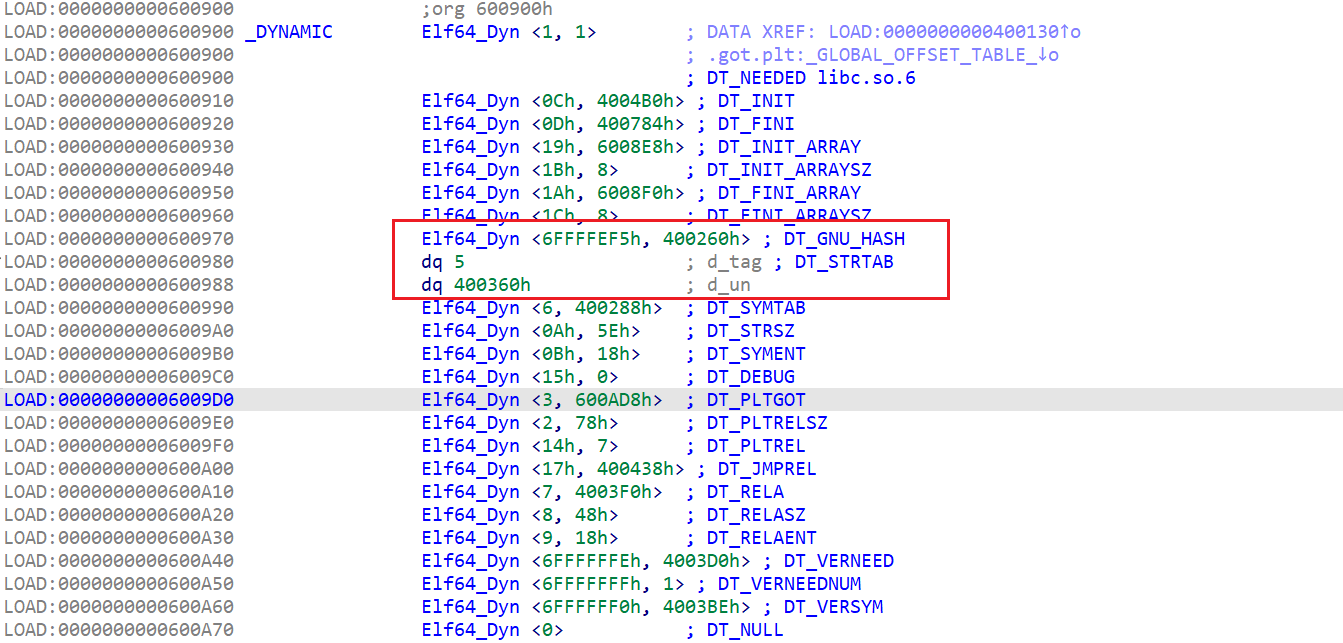
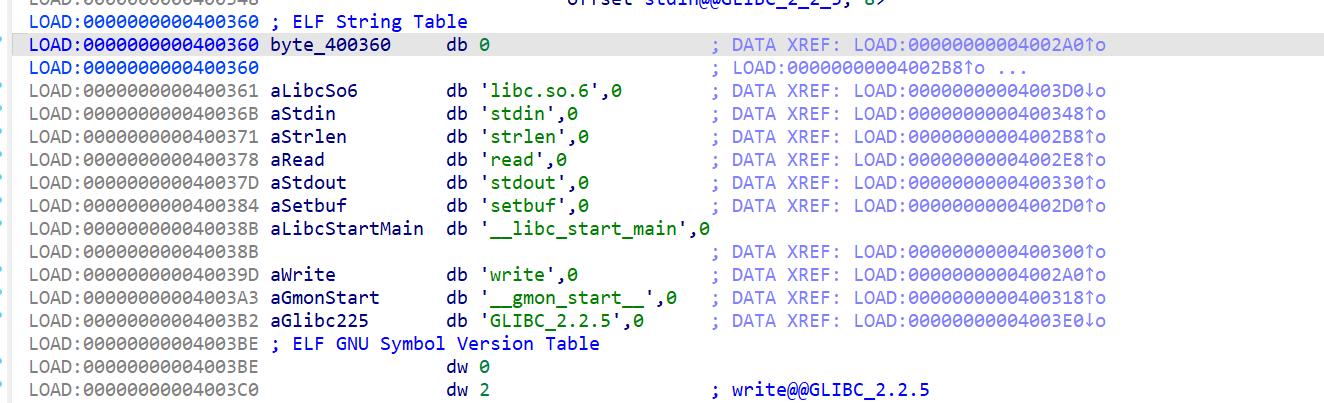
- 首先我们来伪造一下
1 | from pwn import * |
32位程序的利用
相关题目
64位程序
ACTF2025_only_read
DASCTF2025上半年赛_mini
32位程序
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 iyheart的博客!
 wechat
wechat